Week 32.1 Kafka
In this lecture, Harkirat covered the essentials of Apache Kafka, explaining its distributed nature and high-throughput capabilities. He introduced key Kafka jargon, including clusters, brokers, producers, consumers, and topics. Harkirat discussed the importance of offsets for message tracking and retention policies for data management. He demonstrated how to implement Kafka in Node.js applications and explored the concepts of consumer groups and partitions. The lecture concluded with an overview of partitioning strategies, emphasizing their role in Kafka’s scalability and performance.
Understanding Kafka
Apache Kafka is an open-source distributed event streaming platform that has gained significant popularity in the tech industry. It’s designed to handle high-throughput, fault-tolerant, and scalable data pipelines, making it an essential tool for many Fortune 100 companies and beyond.
Key Features
- High Throughput: Kafka can deliver messages at network-limited throughput using a cluster of machines, with latencies as low as 2ms. This makes it ideal for handling large volumes of data in real-time.
- Scalability: One of Kafka’s strongest points is its ability to scale horizontally. You can scale Kafka by adding more nodes that run Kafka brokers, allowing it to handle production clusters with up to a thousand brokers, trillions of messages per day, and petabytes of data.
- Permanent Storage: Kafka stores streams of data safely in a distributed, durable, and fault-tolerant cluster. This ensures data persistence and reliability.
- High Availability: Kafka clusters can be efficiently stretched over availability zones or connected across geographic regions, ensuring continuous operation even in the face of failures.
Distributed Nature:
Kafka’s distributed architecture is a key factor in its scalability and reliability. When we say Kafka is distributed, it means:
- The system is spread across multiple servers or nodes, called brokers.
- Data is partitioned and replicated across these brokers for fault tolerance.
- Processing and storage can be scaled horizontally by adding more brokers to the cluster.
This distributed nature allows Kafka to handle massive amounts of data and provide high availability, making it suitable for large-scale, mission-critical applications.
Event Streaming:
Kafka excels in event streaming scenarios. Event streaming is a design pattern where:
- One process (producer) generates events or messages.
- These events are published to a Kafka topic.
- Multiple consumers can subscribe to this topic and process the events independently.
This decoupled architecture allows for building flexible and scalable systems. For example, in a microservices architecture, different services can consume the same event stream and process it according to their specific needs.
Examples of Kafka Applications:
- Payment Notifications: In a financial system, Kafka can be used to stream payment events. When a payment is processed, an event is published to Kafka. Multiple consumers can then react to this event:
- A notification service can send alerts to users.
- An analytics service can update real-time dashboards.
- A fraud detection system can analyze the payment for suspicious activity.
- Log Aggregation: Kafka can collect logs from various services and applications, allowing for centralized processing and analysis.
- Metrics and Monitoring: System and application metrics can be streamed through Kafka for real-time monitoring and alerting.
- User Activity Tracking: E-commerce platforms can use Kafka to track user clicks, searches, and purchases in real-time, enabling personalized recommendations and dynamic pricing.
- Stock Market Data Processing: Financial institutions can use Kafka to ingest and process real-time stock market data feeds, enabling high-frequency trading algorithms.
In conclusion, Kafka’s distributed nature, high throughput, and scalability make it an excellent choice for building robust, real-time data pipelines and event-driven architectures. Its ability to handle large-scale data streams reliably has made it a cornerstone technology in many modern data architectures
Jargons In Kafka
Jargons in Kafka are essential concepts that form the foundation of Apache Kafka’s architecture and functionality. Let’s explore these key terms in detail:
Cluster and Broker
A Kafka cluster is a collection of one or more Kafka brokers working together to provide distributed data streaming capabilities.
- A Kafka broker is an individual server or container that runs Kafka. It’s responsible for storing and managing data logs, as well as handling requests from producers and consumers.
- A Kafka cluster consists of multiple brokers, which can range from a single broker to hundreds or even thousands, depending on the organization’s needs.
Kafka clusters offer several advantages:
- Speed (low latency): Multiple data streams can be processed by separate servers, reducing data delivery latency.
- Durability: Data is replicated across multiple servers, ensuring stability and data availability even if one server fails.
- Scalability: Kafka balances the load across multiple servers, allowing the system to handle increased workloads.
Producers
Producers are applications that publish (write) data to Kafka topics. They are responsible for generating and sending messages to specific topics within the Kafka cluster. Producers connect to Kafka brokers to push messages onto designated topics.
Consumers
Consumers are applications that subscribe to (read) data from Kafka topics. They retrieve messages from topics and process them according to the application’s requirements. Consumers can be organized into consumer groups to increase messaging throughput.
Topics
A topic in Kafka is a logical channel or category where data is stored and published. It serves as the fundamental unit of event organization in Kafka. Topics are divided into partitions, which allow for parallel processing and improved scalability.
Offsets
Offsets are crucial for keeping track of a consumer’s position within a topic:
- Each message within a partition has a unique identifier called an offset.
- Consumers maintain offsets to remember their position in the topic, representing the last consumed message.
- Kafka can manage offsets automatically, or consumers can manage them manually, providing flexibility in message processing.
Retention
Kafka topics have configurable retention policies that determine how long data is stored before being deleted. This feature allows for both real-time processing and historical data replay, making Kafka suitable for various use cases.
Partitions and Consumer Groups
While not explicitly explained in the given pointers, these concepts are closely related to topics and consumers:
- Partitions are subdivisions of topics that allow for parallel processing and improved scalability. Each partition is an ordered, immutable sequence of messages.
- Consumer groups are collections of consumers that work together to read from a topic. Each consumer in a group reads from exclusive partitions, increasing messaging throughput.
Understanding these jargons is crucial for effectively working with Apache Kafka and designing efficient data streaming architectures. The interplay between these components allows Kafka to provide a scalable, fault-tolerant, and high-performance data streaming platform.
Starting Kafka Locally
To get started with Apache Kafka, we’ll use Docker to run a Kafka instance locally. This approach simplifies the setup process and allows for quick experimentation.
-
Launch Kafka Container
To start a Kafka container, run the following command:
Terminal window docker run -p 9092:9092 apache/kafka:3.7.1This command does the following:
- Pulls the Apache Kafka image (version 3.7.1) if not already present
- Runs a new container from this image
- Maps port 9092 from the container to the host, allowing access to Kafka from outside the container
-
Access the Container Shell
To interact with Kafka, we need to access the container’s shell:
a. First, list running containers:
Terminal window docker psb. Then, access the shell of the Kafka container:
Terminal window docker exec -it container_id /bin/bashReplace
container_idwith the actual ID of your Kafka container.c. Navigate to the Kafka binary directory:
Terminal window cd /opt/kafka/bin -
Create a Kafka Topic
Create a new topic named “quickstart-events”:
Terminal window ./kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092This command:
- Creates a new topic named “quickstart-events”
- Uses the local Kafka broker running on port 9092
-
Publish Messages to the Topic
To send messages to the “quickstart-events” topic:
Terminal window ./kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092After running this command:
- You’ll see a
>prompt - Type your messages and press Enter to send each one
- Use Ctrl+C to exit the producer
- You’ll see a
-
Consume Messages from the Topic
To read messages from the “quickstart-events” topic:
Terminal window ./kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092This command:
- Starts a console consumer
- Reads all messages from the beginning of the topic
- Continues to listen for new messages
- Use Ctrl+C to stop the consumer
These steps provide a hands-on introduction to running Kafka locally and performing basic operations such as creating topics, producing messages, and consuming messages. This setup is ideal for learning and testing Kafka functionality in a controlled environment.
Kafka in Node.js
This section demonstrates how to use Apache Kafka within a Node.js application using the KafkaJS library. KafkaJS is a modern, feature-rich Kafka client for Node.js that supports Kafka 0.10+ and offers native support for 0.11 features.
Project Setup
-
Initialize the project:
Terminal window npm init -ynpx tsc --initThis creates a new Node.js project and initializes TypeScript configuration.
-
Update
tsconfig.json: Add the following configurations:{"compilerOptions": {"rootDir": "./src","outDir": "./dist"}}This sets up the source and output directories for TypeScript compilation.
Implementing Kafka Producer and Consumer
Create a new file src/index.ts with the following content:
import { Kafka } from "kafkajs";
const kafka = new Kafka({ clientId: "my-app", brokers: ["localhost:9092"]});
const producer = kafka.producer();const consumer = kafka.consumer({groupId: "my-app3"});
async function main() { // Producer await producer.connect(); await producer.send({ topic: "quickstart-events", messages: [{ value: "hi there" }] });
// Consumer await consumer.connect(); await consumer.subscribe({ topic: "quickstart-events", fromBeginning: true });
await consumer.run({ eachMessage: async ({ topic, partition, message }) => { console.log({ offset: message.offset, value: message?.value?.toString(), }); }, });}
main();This script does the following:
- Imports the
Kafkaclass from thekafkajspackage. - Creates a Kafka instance with a client ID and broker address.
- Initializes a producer and a consumer.
- In the
mainfunction:- Connects the producer and sends a message to the “quickstart-events” topic.
- Connects the consumer, subscribes to the same topic, and sets up a message handler.
- The consumer prints the offset and value of each received message.
Running the Application
-
Update
package.jsonto include a start script:{"scripts": {"start": "tsc -b && node dist/index.js"}}This script compiles the TypeScript code and runs the resulting JavaScript.
-
Start the application:
Terminal window npm run start
This setup demonstrates a basic Kafka producer and consumer implementation in Node.js. The producer sends a message to a topic, and the consumer reads messages from the same topic, printing them to the console.
Key points to note:
- The application uses TypeScript for type safety.
- It demonstrates both producing and consuming messages in a single application.
- The consumer is set up to read messages from the beginning of the topic.
- Error handling and graceful shutdown are not implemented in this basic example but should be considered for production use.
This example provides a foundation for building more complex Kafka-based applications in Node.js, leveraging the features of the KafkaJS library.
Breaking into Producer and Consumer Scripts
In this section, we’ll separate our Kafka logic into two distinct files: producer.ts and consumer.ts. This separation allows for more focused and modular code, enabling independent execution of producing and consuming operations.
Producer Script (producer.ts)
import { Kafka } from "kafkajs";
const kafka = new Kafka({ clientId: "my-app", brokers: ["localhost:9092"]});
const producer = kafka.producer();
async function main() { await producer.connect(); await producer.send({ topic: "quickstart-events", messages: [{ value: "hi there" }] });}
main();Key points:
- Initializes a Kafka instance with a client ID and broker address.
- Creates a producer instance.
- Connects the producer and sends a single message to the “quickstart-events” topic.
- The message value is hardcoded as “hi there” for this example.
Consumer Script (consumer.ts)
import { Kafka } from "kafkajs";
const kafka = new Kafka({ clientId: "my-app", brokers: ["localhost:9092"]});
const consumer = kafka.consumer({ groupId: "my-app3" });
async function main() { await consumer.connect(); await consumer.subscribe({ topic: "quickstart-events", fromBeginning: true });
await consumer.run({ eachMessage: async ({ topic, partition, message }) => { console.log({ offset: message.offset, value: message?.value?.toString(), }); }, });}
main();Key points:
- Uses the same Kafka instance configuration as the producer.
- Creates a consumer instance with a specific group ID (“my-app3”).
- Connects the consumer and subscribes to the “quickstart-events” topic.
- Sets up a message handler to log the offset and value of each received message.
- The
fromBeginning: trueoption ensures that the consumer reads all messages from the start of the topic.
Updated package.json
To run these scripts independently, update the package.json file:
{ "scripts": { "start": "tsc -b && node dist/index.js", "produce": "tsc -b && node dist/producer.js", "consume": "tsc -b && node dist/consumer.js" }}This update adds two new scripts:
produce: Compiles and runs the producer script.consume: Compiles and runs the consumer script.
Running Multiple Consumers
To test the setup with multiple consumers:
-
Open multiple terminal windows.
-
In each window, run the consumer script:
Terminal window npm run consume -
In a separate window, run the producer script:
Terminal window npm run produce
Observations:
- Each consumer instance will receive the message produced.
- However, since we specified a consumer group (“my-app3”), Kafka will ensure that each message is only processed once within the group.
- If you run multiple producers, each consumer in the group will receive a subset of the messages, demonstrating Kafka’s load balancing capabilities.
Consumer Groups
The use of a consumer group (“my-app3” in this case) is significant:
- Consumer groups allow Kafka to distribute the processing load across multiple consumer instances.
- Each partition of a topic is assigned to only one consumer within a group.
- If there are more consumers than partitions, some consumers will be idle.
- This setup enables horizontal scaling of message processing.
By separating the producer and consumer logic, we’ve created a more flexible setup that allows for independent scaling and management of message production and consumption. This separation is crucial in real-world applications where producers and consumers often run on different machines or as separate microservices.
Consumer Groups and Partitions
Consumer Groups
A consumer group in Kafka is a collection of consumers that work together to consume messages from one or more topics. Consumer groups serve several important purposes:
- Load Balancing: They distribute the processing load among multiple consumers, allowing for efficient handling of high message volumes.
- Fault Tolerance: If a consumer in the group fails, Kafka automatically redistributes its partitions to the remaining active consumers, ensuring continuous processing.
- Parallel Processing: Consumers in a group can process different partitions simultaneously, improving overall throughput and scalability.
Consumer Group Illustration
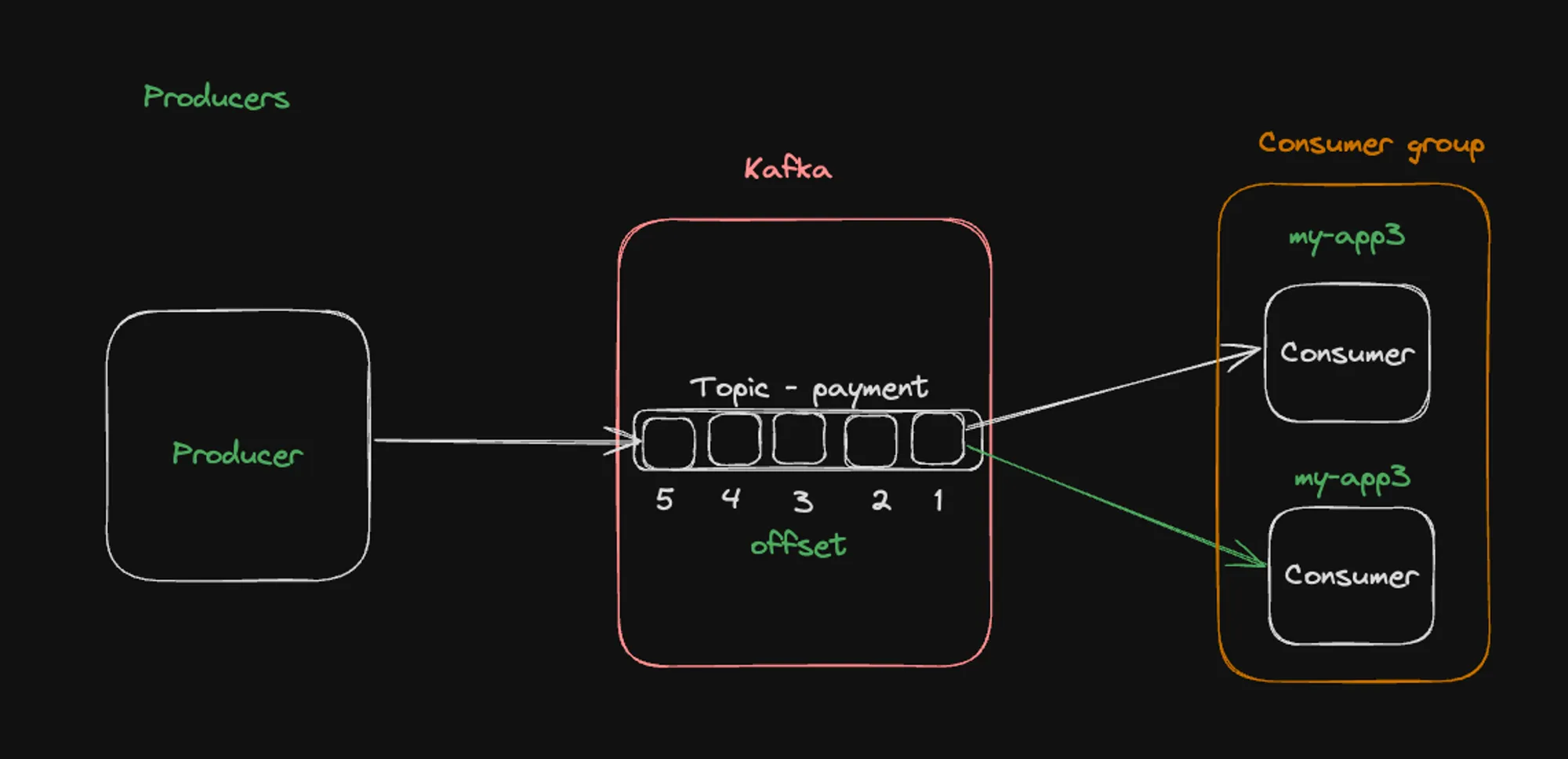
The first architecture illustrates a basic Kafka setup with a producer, a topic (payment), and a consumer group (my-app3). Here’s what we can observe:
- A single producer sends messages to the “payment” topic.
- The topic is divided into multiple partitions (shown as numbered boxes 1-5).
- Two consumers in the “my-app3” group are consuming messages from different partitions.
- This setup demonstrates how consumer groups enable parallel processing and load balancing across multiple consumers.
Partitions
Partitions are fundamental units of parallelism in Kafka. They are subdivisions of a topic, each representing an ordered, immutable sequence of messages. Key characteristics of partitions include:
- They allow Kafka to scale horizontally by distributing data across multiple brokers.
- Each partition can be processed independently, enabling parallel consumption of data.
How is a partition decided?
When a message is produced to a Kafka topic, it’s assigned to a specific partition. This assignment can be done in several ways:
- Round-robin method: Distributes messages evenly across all partitions.
- Hash of the message key: Ensures messages with the same key always go to the same partition.
- Custom partitioning strategy: Allows for specific business logic in partition assignment.
Partition Decision Illustration
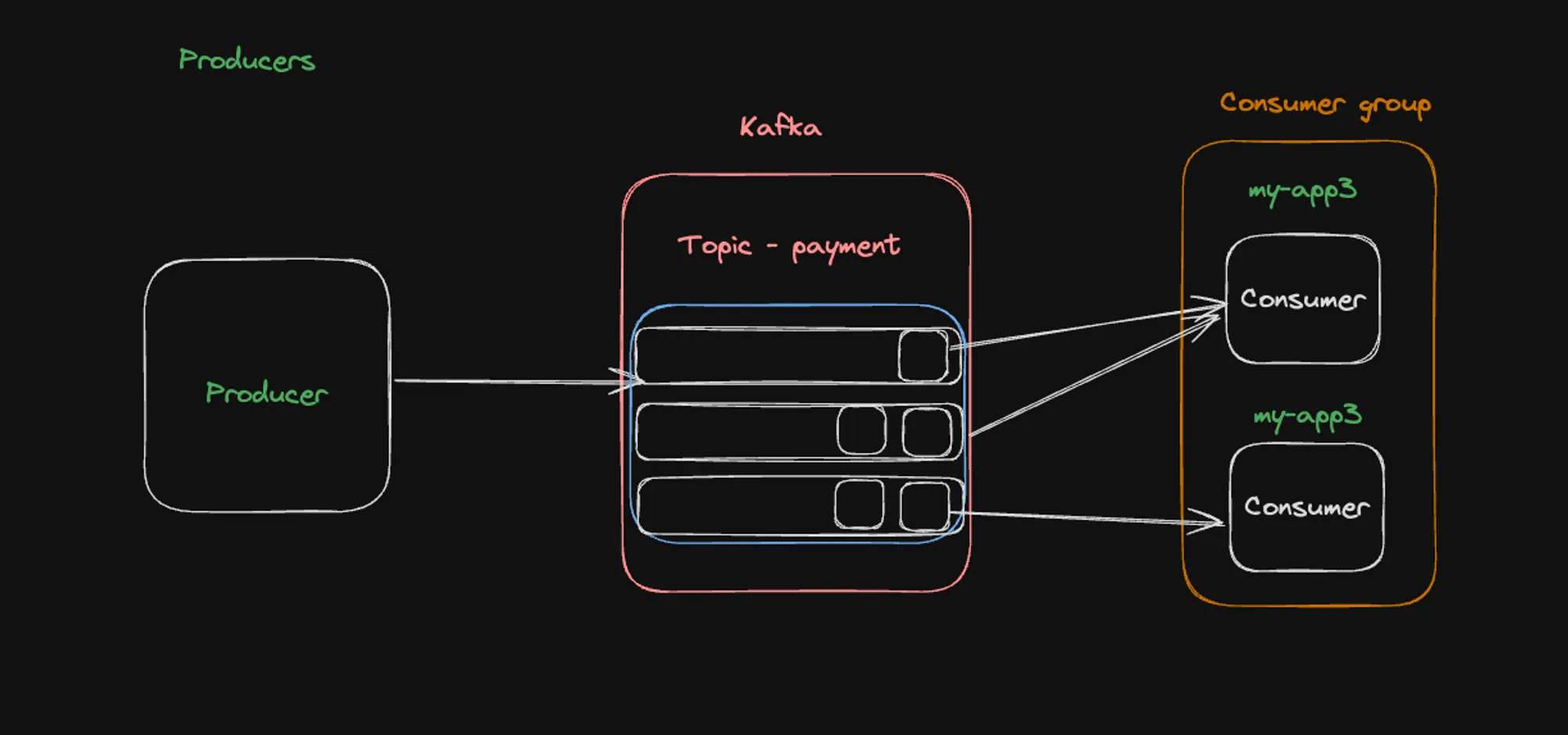
This architecture shows a more detailed view of how messages are distributed across partitions:
- The producer sends messages to the Kafka topic.
- Messages are distributed across three partitions (represented by the blue rectangles).
- Each partition contains a sequence of messages (shown as small boxes within the partitions).
- The arrows indicate how consumers in the group are assigned to specific partitions.
This image emphasizes the importance of message keys in determining partition assignment. As mentioned in the notes, using a user ID as the message key ensures that all messages from the same user go to the same partition, and consequently, to the same consumer. This strategy prevents issues like a single user’s messages overwhelming multiple consumers.
Multiple Consumer Groups
Kafka allows multiple consumer groups to read from the same topic independently. This feature enables different applications or services to process the same data for various purposes without interfering with each other.
Multiple Consumer Groups Illustration
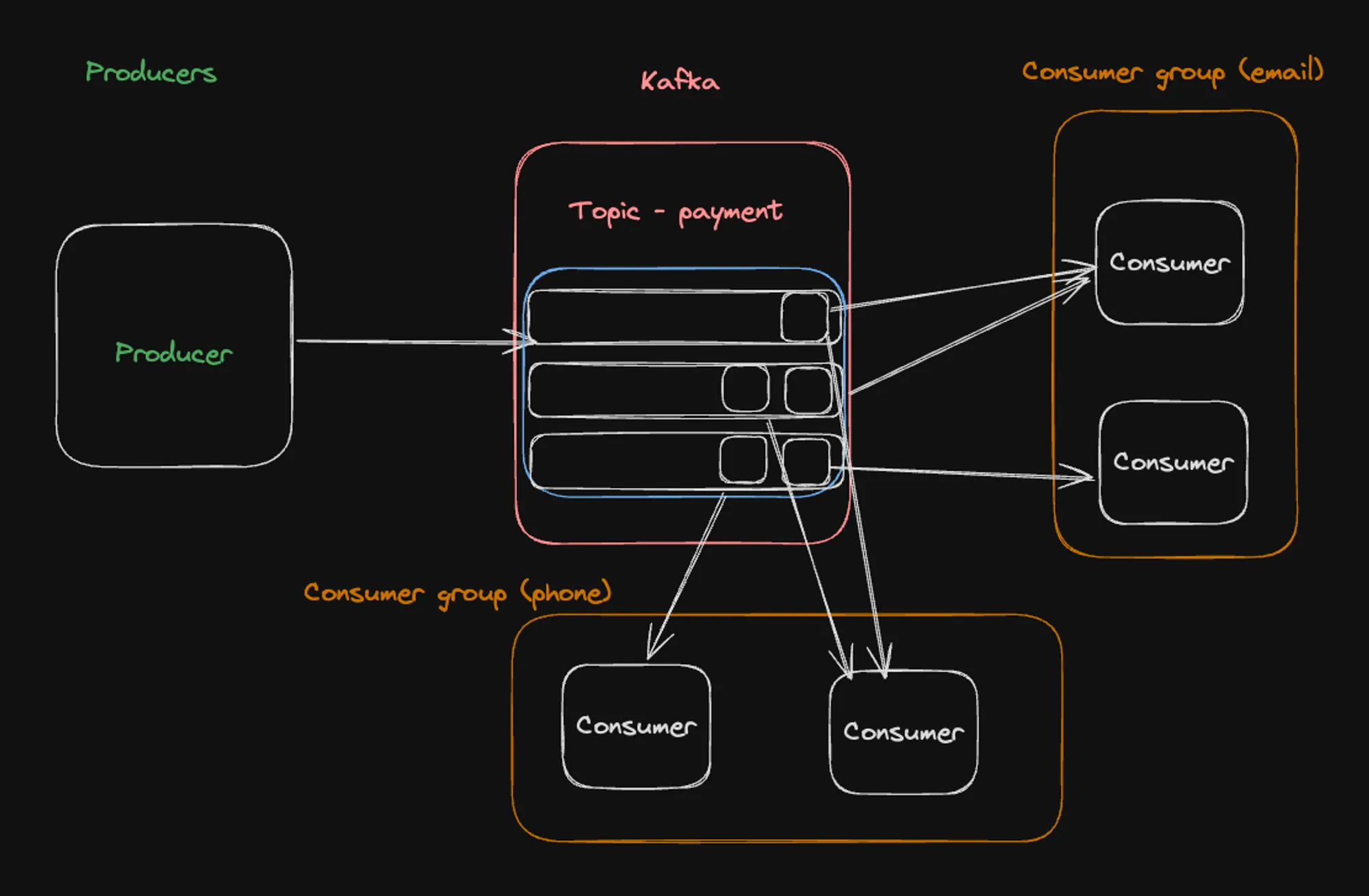
Theis architecture demonstrates how multiple consumer groups can coexist:
- A single producer sends messages to the “payment” topic.
- The topic is divided into three partitions.
- Two separate consumer groups are shown: one labeled “email” and another labeled “phone”.
- Each consumer group has its own set of consumers reading from the partitions.
- The “email” group has two consumers, while the “phone” group has two consumers.
This setup illustrates how different applications (e.g., an email notification service and a phone notification service) can independently consume the same data from Kafka. Each group maintains its own offset and can process messages at its own pace without affecting the other group.
The combination of consumer groups and partitions in Kafka provides a powerful mechanism for scalable, fault-tolerant, and flexible data processing. It allows for efficient distribution of workload, parallel processing, and the ability to serve multiple use cases from the same data stream.
Partitions in Kafka
Partitions are a fundamental concept in Kafka that allow for scalability and parallel processing of data. They are subdivisions of a topic, enabling data distribution across multiple brokers and parallel consumption by multiple consumers.
Creating a Topic with Multiple Partitions
To create a new topic with 3 partitions:
./kafka-topics.sh --create --topic payment-done --partitions 3 --bootstrap-server localhost:9092To verify the partitions:
./kafka-topics.sh --describe --topic payment-done --bootstrap-server localhost:9092Updating Node.js Scripts
Update the producer and consumer scripts to use the new “payment-done” topic:
Producer:
async function main() { await producer.connect(); await producer.send({ topic: "payment-done", messages: [{ value: "hi there", key: "user1" }] });}Consumer:
await consumer.subscribe({ topic: "payment-done", fromBeginning: true})Testing with Multiple Consumers
-
Open three terminal windows and run in each:
npm run consume -
In another terminal, produce messages:
npm run produce
Observe that messages are distributed among the three consumers.
Current Architecture
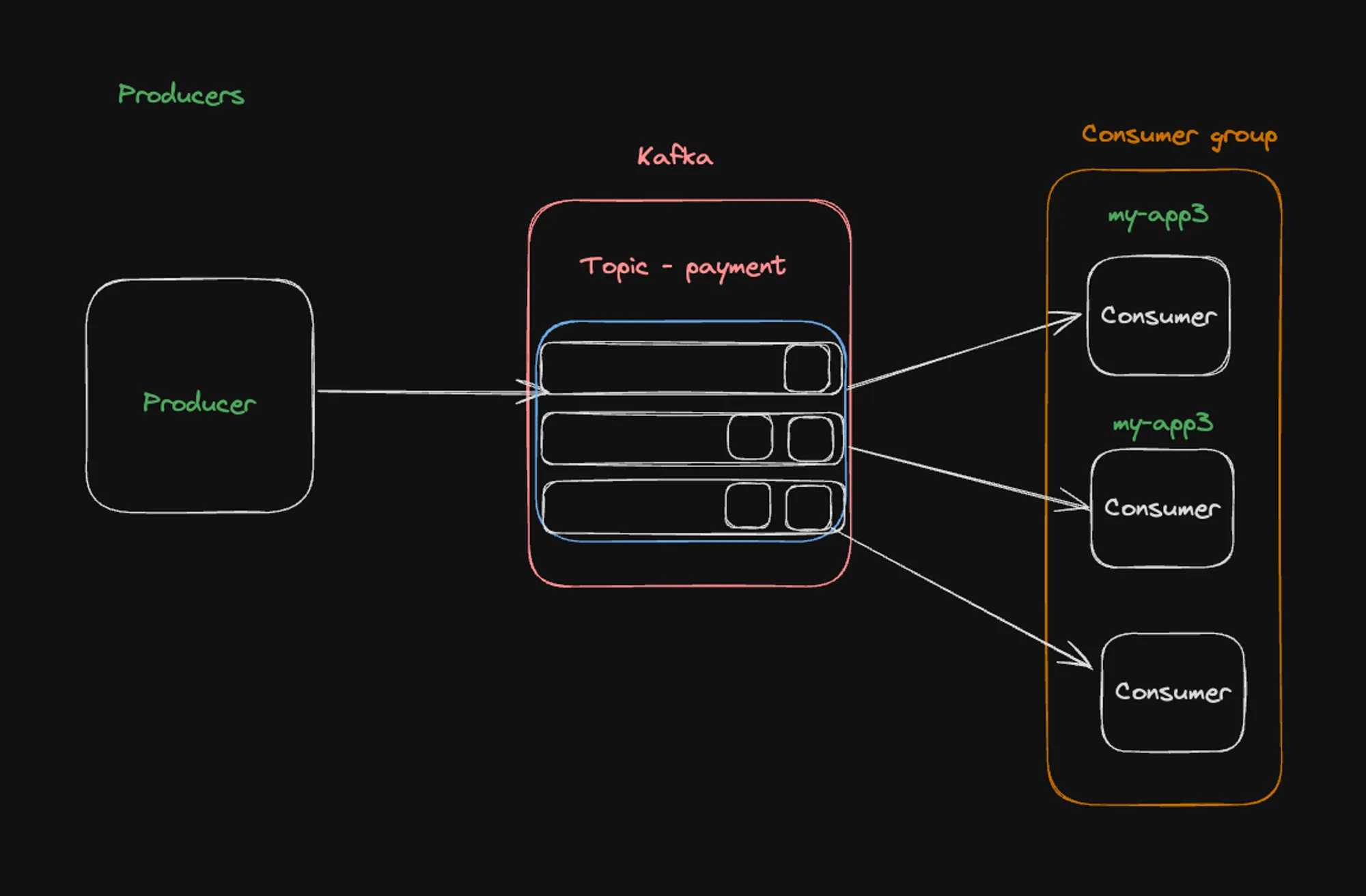
- A single producer sending messages to the “payment-done” topic.
- The topic divided into three partitions.
- Three consumers in the “my-app3” group, each assigned to a partition.
This setup demonstrates how Kafka distributes messages across partitions and how consumers in a group share the load of processing these partitions.
Assignment: Partition Reassignment
To observe partition reassignment:
- Start with all three consumers running.
- Stop one or two consumers.
- Observe how Kafka reassigns partitions to the remaining consumers.
To check consumer group details:
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-app3This command will show which consumer is assigned to which partition, allowing you to observe the reassignment process.
Key takeaways:
- Partitions enable parallel processing and scalability in Kafka.
- Consumers in a group automatically balance the load of processing partitions.
- Kafka handles consumer failures by reassigning partitions to active consumers.
Scenarios of Partition and Consumer Relationships
Let’s discuss the three scenarios of partition and consumer relationships in Kafka, using the provided images to illustrate each case:
1] Equal number of partitions and consumers
In this ideal scenario, there’s a one-to-one mapping between partitions and consumers:
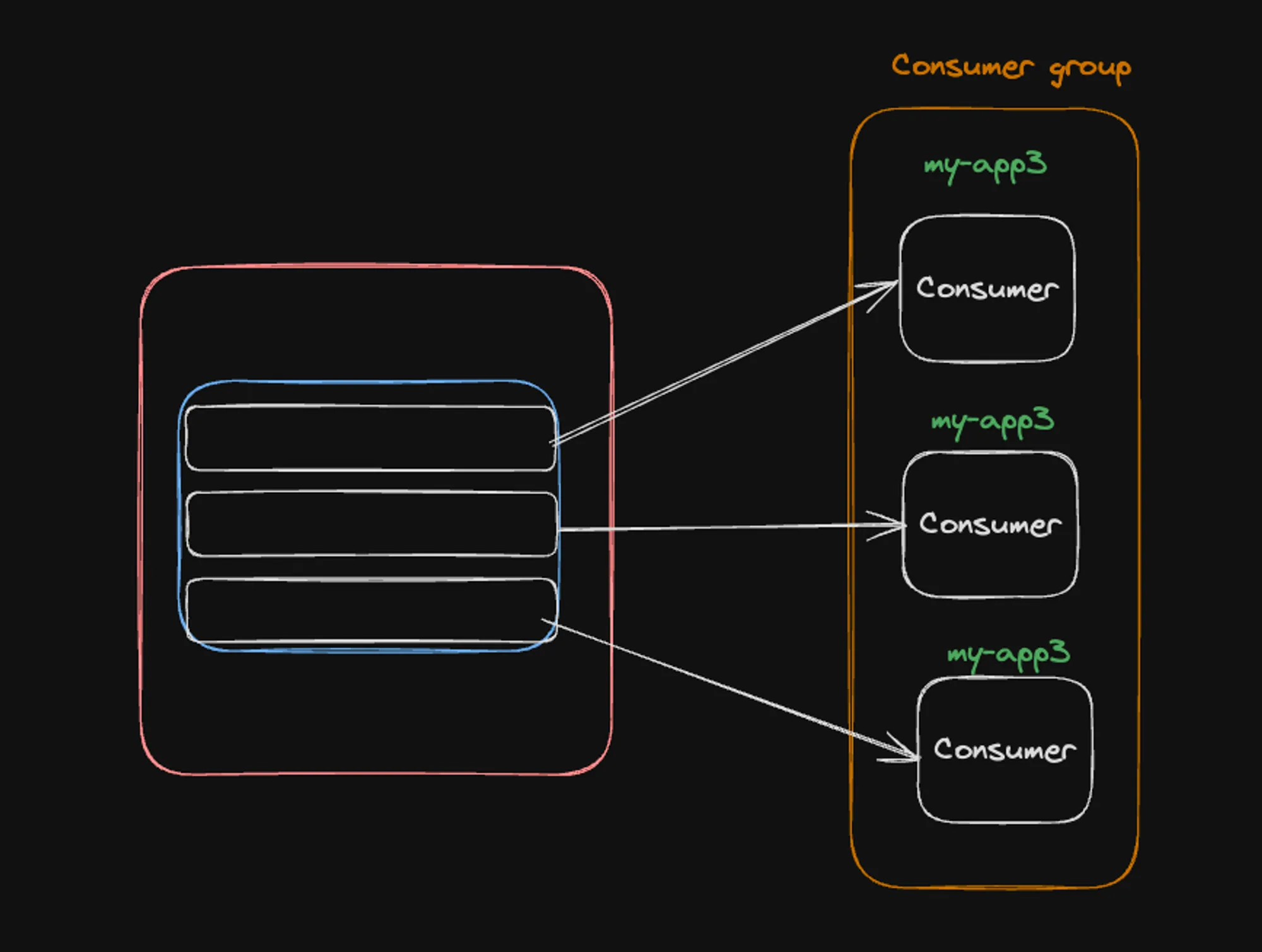
- The image shows 3 partitions and 3 consumers in the “my-app3” consumer group.
- Each consumer is assigned exactly one partition.
- This setup allows for optimal parallelism, as each consumer can process messages from its dedicated partition independently.
- Load is evenly distributed among all consumers.
2] More partitions than consumers
When there are more partitions than consumers:
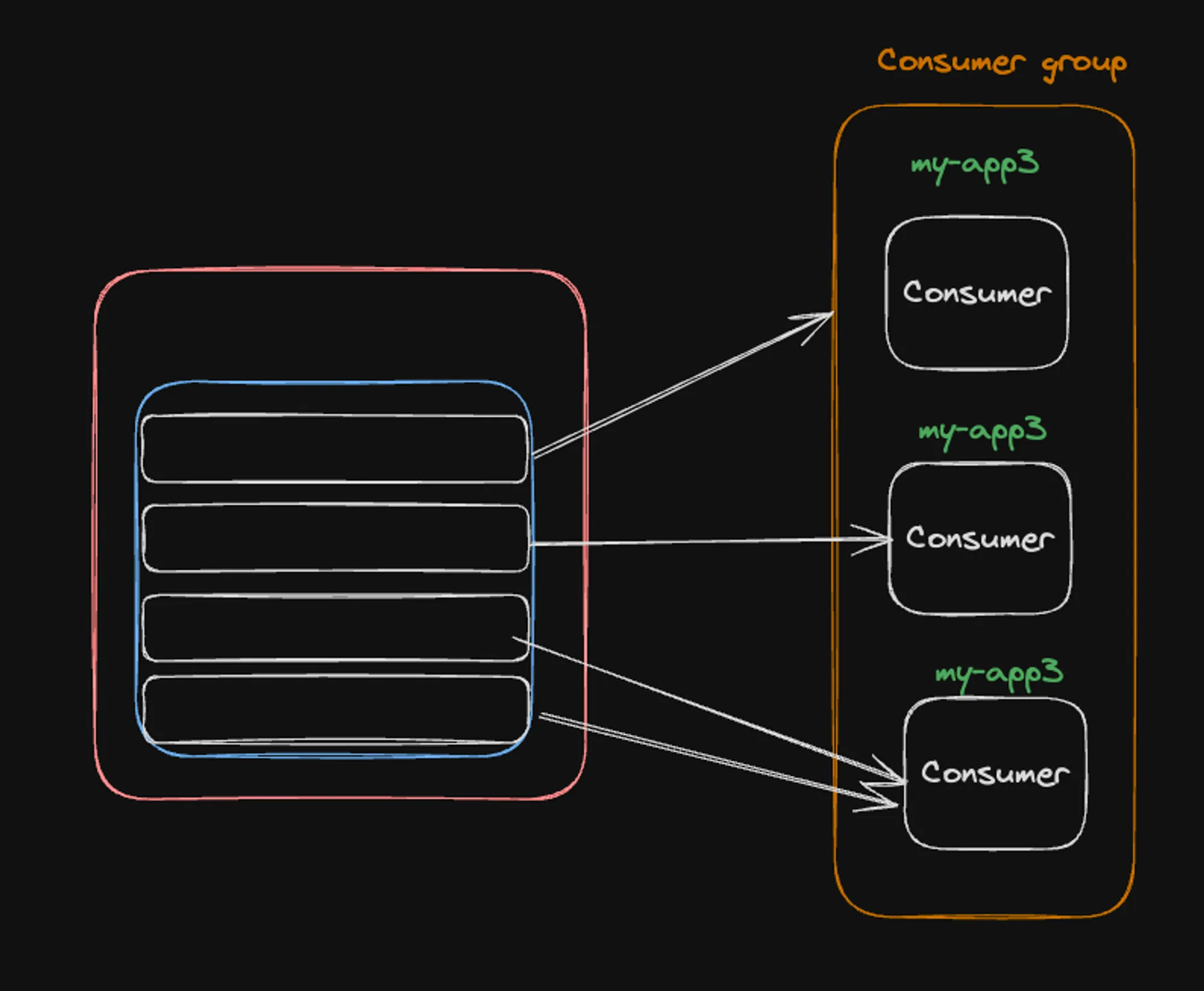
- The image depicts 4 partitions but only 3 consumers in the “my-app3” group.
- Some consumers will be assigned multiple partitions.
- In this case, the third consumer is handling two partitions, while the others handle one each.
- This scenario still allows for parallelism, but some consumers may have a higher workload.
- Kafka’s partition assignment strategy aims to distribute partitions as evenly as possible among available consumers.
3] More consumers than partitions
In the case where there are more consumers than partitions:
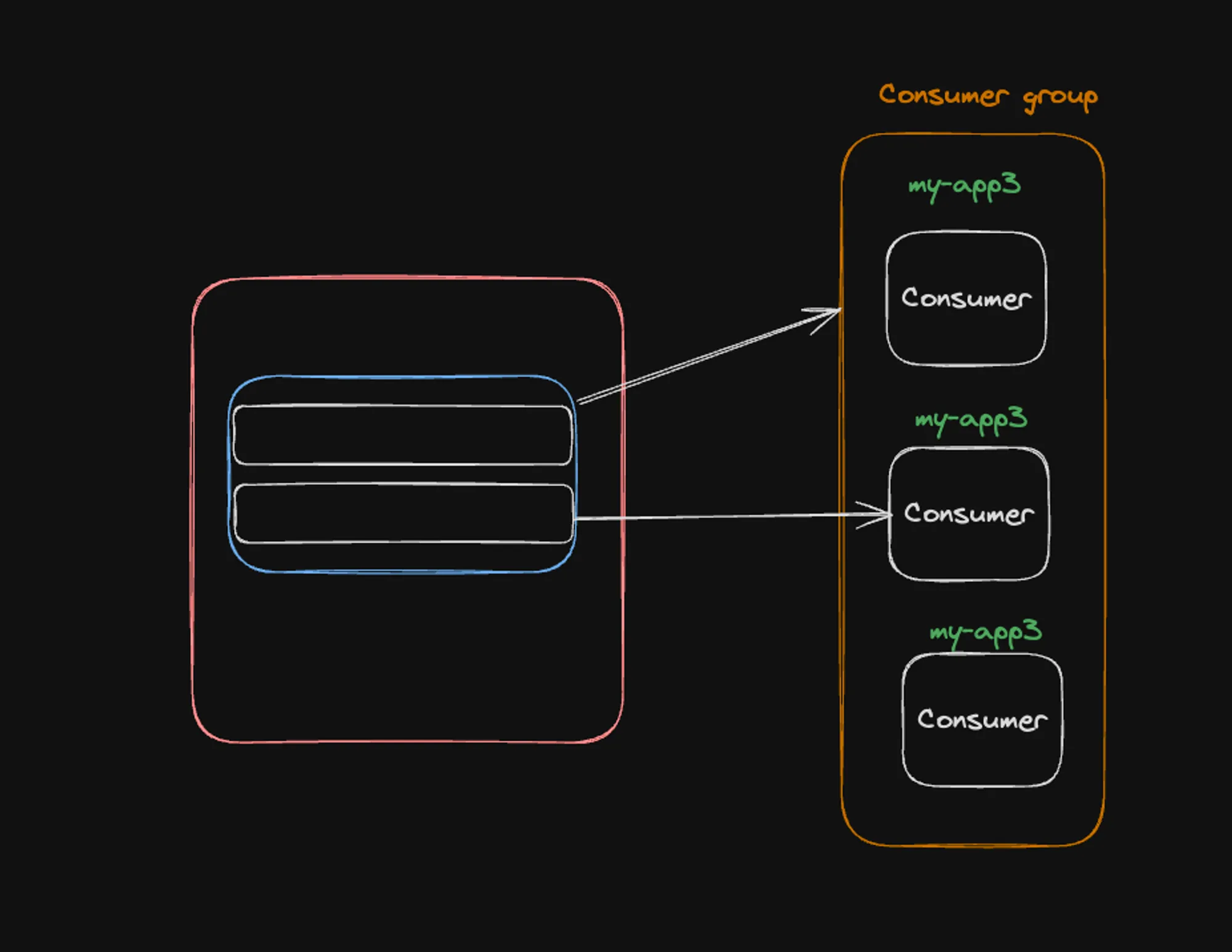
- The image shows 2 partitions but 3 consumers in the “my-app3” group.
- Only two consumers are actively assigned partitions, while the third consumer remains idle.
- This situation is less efficient, as not all consumers are utilized.
- Adding more consumers beyond the number of partitions doesn’t increase parallelism or throughput.
Key takeaways:
- The number of partitions determines the maximum parallelism within a consumer group.
- For optimal performance, it’s generally recommended to have at least as many partitions as the expected number of consumers.
- Having more partitions than consumers allows for easy scaling by adding more consumers to the group.
- Having more consumers than partitions results in idle consumers, which is inefficient resource utilization.
These scenarios highlight the importance of properly sizing the number of partitions when designing Kafka topics, considering factors like expected throughput, scalability needs, and the number of consumers that will process the data.
Partitioning Strategy
Kafka uses a partitioning strategy to determine which partition a message should be sent to within a topic. This strategy is crucial for maintaining order and optimizing performance.
Key-Based Partitioning
- When producing messages, you can assign a key that uniquely identifies the event.
- Kafka will hash this key and use the hash to determine the partition.
- This ensures that all messages with the same key (e.g., for the same user) are sent to the same partition.
Importance of Key-Based Partitioning
The question arises: Why would you want messages from the same user to go to the same partition?
- Load Balancing: If a single user generates a high volume of messages (e.g., many notifications), this approach ensures they only impact a single partition rather than overwhelming all partitions.
- Ordering: Messages for a specific key (user) will be processed in the order they were sent, which is crucial for many applications.
- Scalability: It allows for more efficient scaling of consumers, as each consumer can handle a specific set of users.
Implementation Example
Here’s how to implement key-based partitioning in a Node.js Kafka producer:
- Create a new file
producer-user.ts:
import { Kafka } from "kafkajs";
const kafka = new Kafka({ clientId: "my-app", brokers: ["localhost:9092"]})
const producer = kafka.producer();
async function main() { await producer.connect(); await producer.send({ topic: "payment-done", messages: [{ value: "hi there", key: "user1" }] });}
main();- Update
package.jsonto include a new script:
"scripts": { "produce:user": "tsc -b && node dist/producer-user.js"}Testing the Strategy
To observe the effects of key-based partitioning:
-
Start 3 consumers in separate terminals:
Terminal window npm run consume -
Run the user-specific producer:
Terminal window npm run produce:user
You should notice that all messages with the same key (in this case, “user1”) reach the same consumer. This demonstrates that Kafka is consistently routing messages with the same key to the same partition, which is then processed by a specific consumer.
Key takeaways:
- Key-based partitioning ensures consistent routing of related messages.
- It helps in maintaining message order for specific entities (like users).
- This strategy can prevent a single high-volume entity from impacting the entire system’s performance.
By implementing this strategy, you can build more robust and scalable Kafka-based systems that efficiently handle varying loads across different users or entities.