Week 27.2 Kubernates Part 2
In this lecture, Harkirat dives deeper into Kubernetes, focusing on key concepts essential for deploying and managing applications at scale. He covers Kubernetes Deployments and ReplicaSets, demonstrating how to create and manage these resources effectively. The lecture also explores Kubernetes Services, with a particular emphasis on the LoadBalancer service type.
Checkpoint: Key Kubernetes Concepts
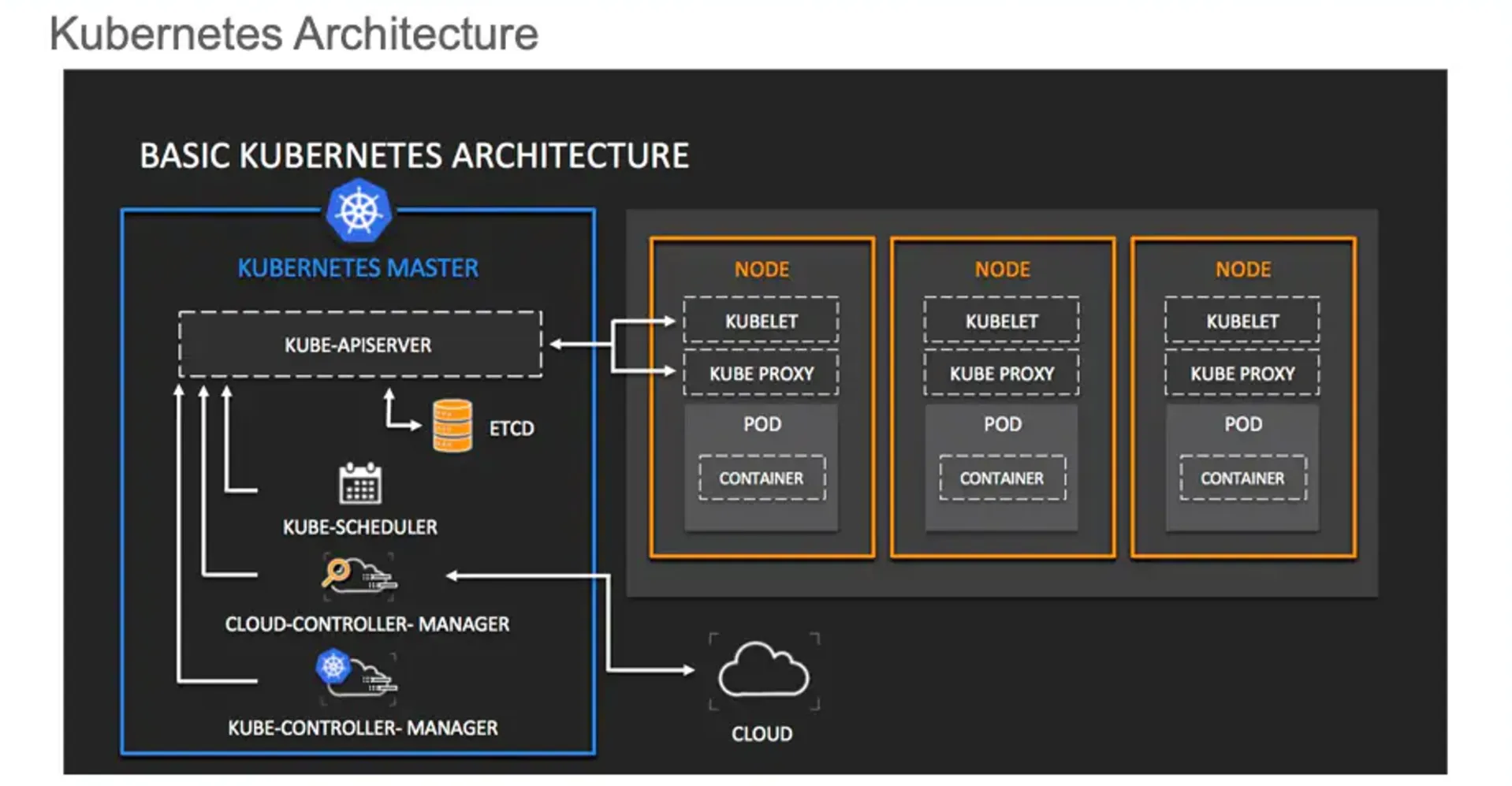
Let’s summarize the key terms we’ve covered so far in our journey to understand Kubernetes:
-
Cluster
- Definition: A set of machines (nodes) that run containerized applications managed by Kubernetes.
- Key points:
- Consists of at least one control plane node and multiple worker nodes.
- Provides a unified platform for deploying and managing containerized applications.
A Kubernetes cluster is a set of machines, called nodes, that run containerized applications managed by Kubernetes. It consists of at least one control plane node and multiple worker nodes, providing a unified platform for deploying and managing containerized applications. This structure allows for efficient orchestration and scaling of applications across the cluster.
-
Nodes
- Definition: Physical or virtual machines that make up a Kubernetes cluster.
- Types:
- Control Plane Node: Manages the cluster state and control processes.
- Worker Nodes: Run the actual application workloads (pods).
- Key components:
- Kubelet: Ensures containers are running in a pod.
- Kube-proxy: Maintains network rules on nodes.
- Container runtime: Software responsible for running containers.
-
Images
- Definition: Lightweight, standalone, executable packages that include everything needed to run a piece of software.
- Key points:
- Contains application code, runtime, libraries, and dependencies.
- Stored in container registries (e.g., Docker Hub).
- Used to create containers.
-
Containers
- Definition: Runnable instances of images.
- Key points:
- Provide consistent environments across different computing environments.
- Isolate applications from one another and the underlying infrastructure.
- Managed by container runtimes like Docker or containerd.
-
Pods
- Definition: The smallest deployable units in Kubernetes, representing a single instance of a running process in a cluster.
- Key points:
- Can contain one or more containers.
- Share network namespace and storage.
- Ephemeral by nature (can be created, destroyed, and replaced dynamically).
- Scheduled onto nodes in the cluster.
Relationships Between These Concepts:
- A Kubernetes cluster is composed of nodes.
- Nodes run pods.
- Pods contain one or more containers.
- Containers are created from images.
Practical Application:
We’ve learned how to:
- Create a Kubernetes cluster (using tools like kind or minikube).
- Interact with the cluster using kubectl.
- Deploy a simple pod running an NGINX container.
This foundation sets the stage for more advanced Kubernetes concepts and operations, such as deployments, services, and scaling applications.
Kubernetes Deployments
Deployments are a crucial concept in Kubernetes, providing a higher level of abstraction for managing pods. Let’s dive into the key aspects of Deployments and how they differ from individual pods.
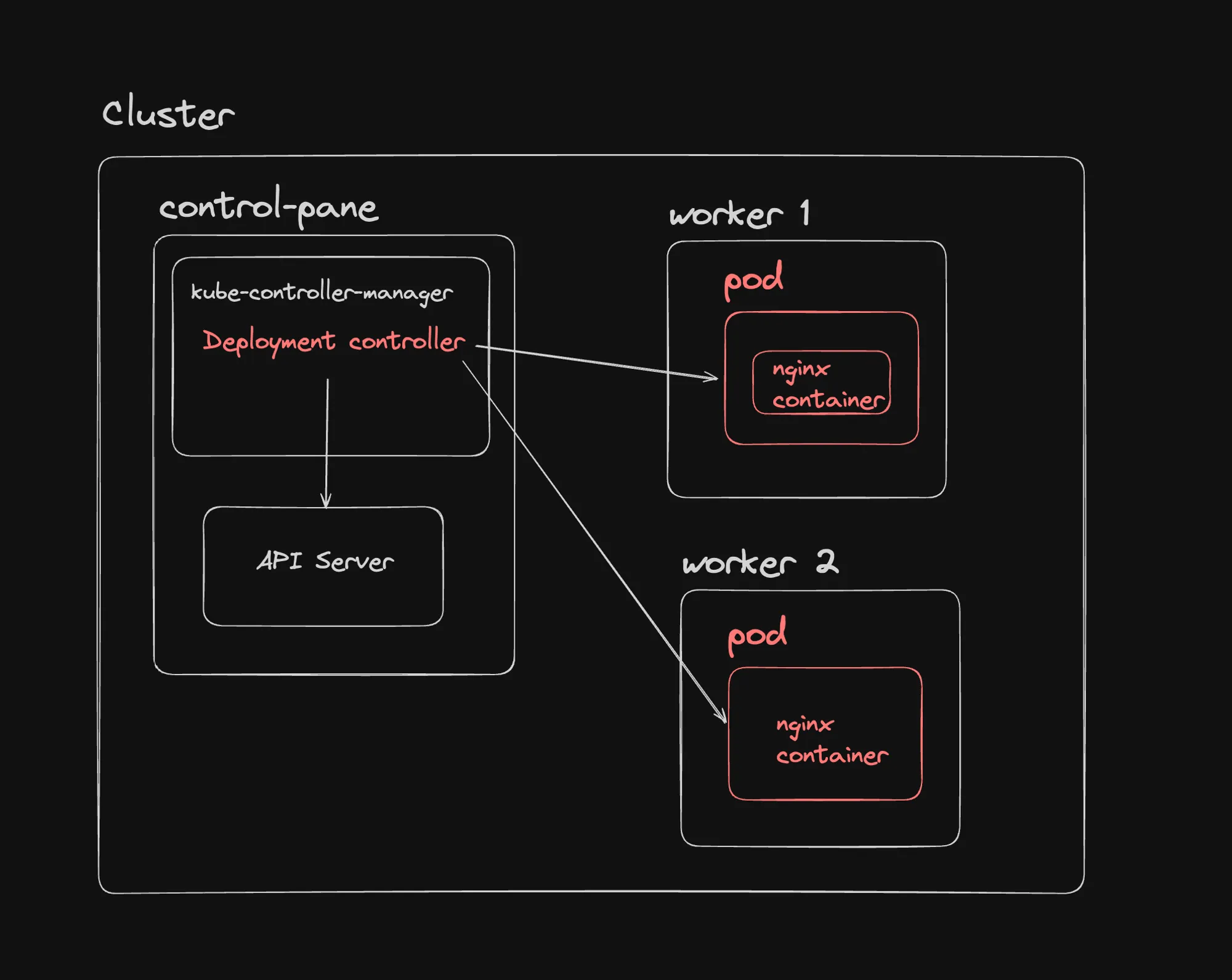
What is a Deployment?
A Deployment in Kubernetes is a resource object that provides declarative updates to applications. It allows you to:
- Describe an application’s life cycle
- Define the desired state for your pods and ReplicaSets
- Update that state in a controlled manner
Deployment vs. Pod: Key Differences
- Abstraction Level
- Pod: The smallest deployable unit in Kubernetes.
- Deployment: A higher-level controller managing multiple pods.
- Management
- Pod: Ephemeral and can be frequently created/destroyed.
- Deployment: Ensures a specified number of pod replicas are running.
- Updates
- Pod: Direct updates require manual intervention and can cause downtime.
- Deployment: Supports rolling updates for gradual changes and easy rollbacks.
- Scaling
- Pod: Manual scaling by creating/deleting individual pods.
- Deployment: Easy scaling by specifying desired replicas; automatic adjustment.
- Self-Healing
- Pod: Requires manual restart if crashed (unless managed by a controller).
- Deployment: Automatically replaces failed pods to maintain desired state.
Benefits of Using Deployments
- Declarative Updates: Define the desired state, and Kubernetes works to maintain it.
- Rolling Updates and Rollbacks: Easily update applications with minimal downtime and roll back if issues occur.
- Scaling: Quickly scale applications up or down.
- Self-Healing: Automatic replacement of failed pods.
- Version Control: Track and control changes to your application deployments.
Creating a Deployment
Here’s a basic example of creating a Deployment:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deploymentspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.14.2 ports: - containerPort: 80Apply this with:
kubectl apply -f nginx-deployment.yamlManaging Deployments
-
Scaling:
kubectl scale deployment nginx-deployment --replicas=5 -
Updating:
kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 -
Rolling Back:
kubectl rollout undo deployment/nginx-deployment -
Checking Status:
kubectl rollout status deployment/nginx-deployment
Best Practices
- Use Labels: Properly label your Deployments and Pods for easy management and selection.
- Set Resource Limits: Define CPU and memory limits to ensure efficient resource allocation.
- Use Readiness and Liveness Probes: Ensure your application is healthy and ready to serve traffic.
- Version Control: Keep your Deployment YAML files in version control.
- Use Rolling Updates: Minimize downtime by using rolling update strategy.
ReplicaSets in Kubernetes
ReplicaSets are a crucial component in Kubernetes’ ability to maintain the desired state of your application. Let’s dive into what ReplicaSets are, how they work, and their relationship with Deployments and Pods.
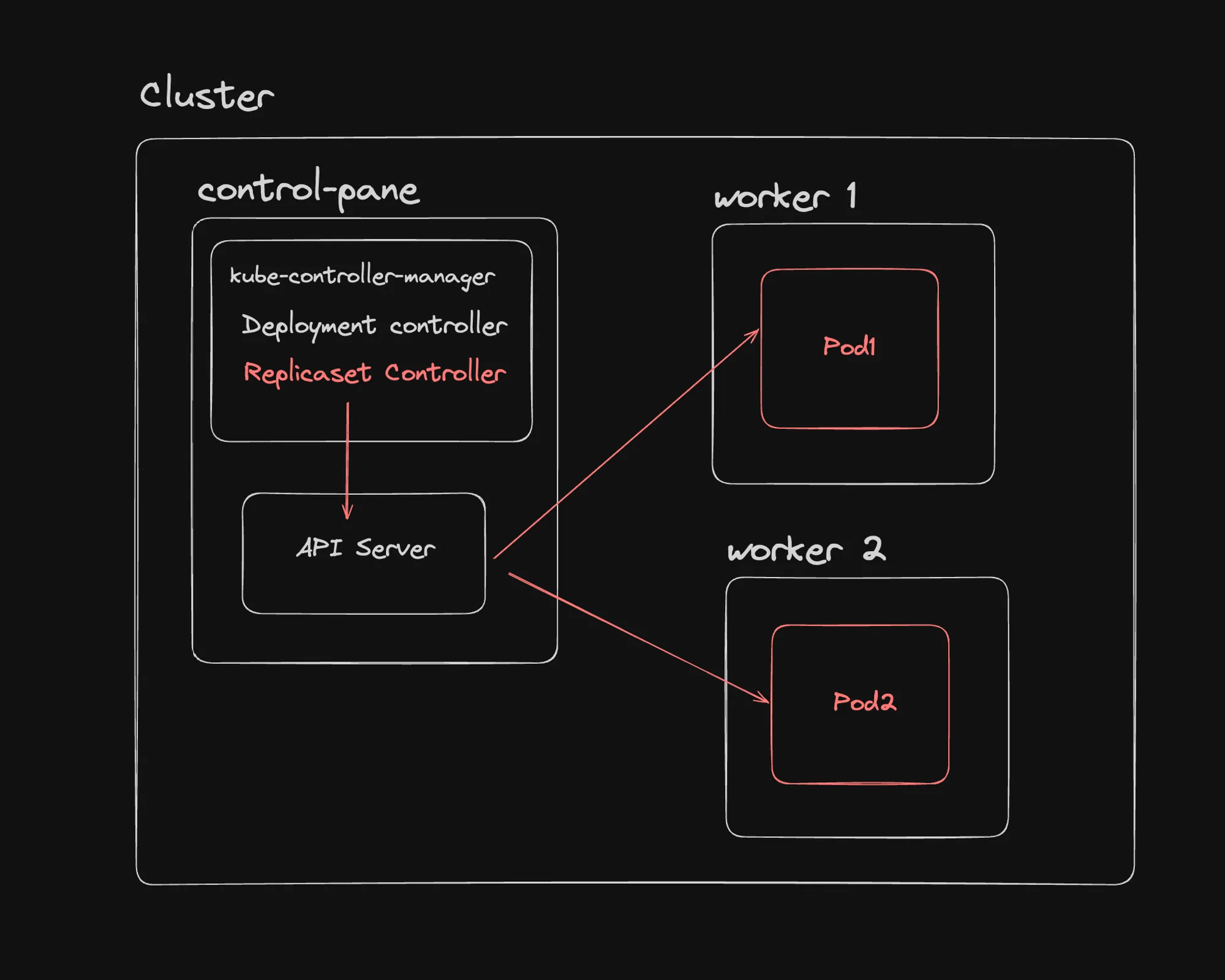
What is a ReplicaSet?
A ReplicaSet is a Kubernetes controller that ensures a specified number of identical Pods are running at any given time. It’s responsible for maintaining the stability and availability of a set of Pods.
Key features of ReplicaSets:
- Ensures a specified number of Pod replicas are running
- Automatically replaces Pods that fail or are deleted
- Can be scaled up or down by changing the desired number of replicas
ReplicaSets in the Kubernetes Hierarchy
The relationship between Deployments, ReplicaSets, and Pods can be visualized as follows:
Deployment └── ReplicaSet └── PodsHow ReplicaSets Work
- Creation: When you create a Deployment, it automatically creates a ReplicaSet.
- Pod Management: The ReplicaSet creates and manages the specified number of Pods based on the template defined in the Deployment.
- Monitoring: The ReplicaSet constantly monitors the state of its Pods.
- Self-Healing: If a Pod fails or is deleted, the ReplicaSet automatically creates a new Pod to maintain the desired number of replicas.
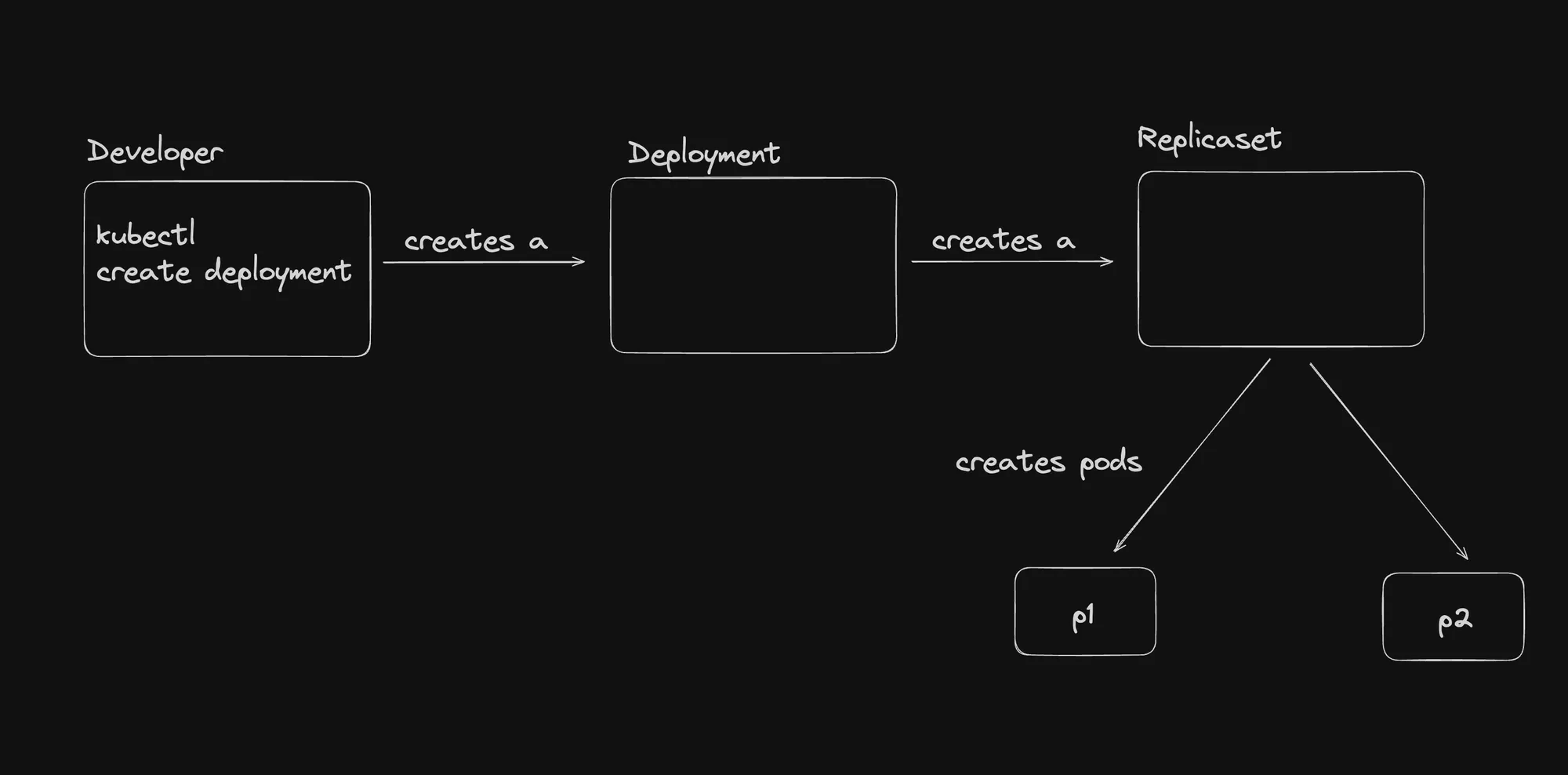
Series of Events
- User creates a Deployment.
- Deployment creates a ReplicaSet.
- ReplicaSet creates the specified number of Pods.
- If Pods go down, the ReplicaSet controller ensures to bring them back up.
Example ReplicaSet YAML
While you typically won’t create ReplicaSets directly (as they’re managed by Deployments), here’s what a ReplicaSet definition looks like:
apiVersion: apps/v1kind: ReplicaSetmetadata: name: frontend labels: app: guestbook tier: frontendspec: replicas: 3 selector: matchLabels: tier: frontend template: metadata: labels: tier: frontend spec: containers: - name: php-redis image: gcr.io/google_samples/gb-frontend:v3Key Concepts
- Selector: ReplicaSets use selectors to identify which Pods to manage.
- Template: Defines the Pod specification that the ReplicaSet will use to create new Pods.
- Replicas: Specifies the desired number of Pod replicas.
ReplicaSets vs. Deployments
While ReplicaSets are powerful, Deployments are generally preferred because they provide additional features:
- Deployments manage ReplicaSets and provide declarative updates to Pods.
- Deployments allow for easy rolling updates and rollbacks.
- Deployments automatically create a new ReplicaSet when the Pod template changes.
Best Practices
- Use Deployments: Instead of directly creating ReplicaSets, use Deployments to manage them.
- Label Properly: Use clear and consistent labels to help ReplicaSets identify their Pods.
- Set Resource Limits: Define CPU and memory limits in your Pod templates to ensure efficient resource allocation.
- Use Probes: Implement readiness and liveness probes in your Pods to help the ReplicaSet make informed decisions about Pod health.
Conclusion
ReplicaSets are a fundamental building block in Kubernetes that ensure the desired number of Pods are always running. While you typically interact with Deployments rather than ReplicaSets directly, understanding how ReplicaSets work is crucial for grasping Kubernetes’ self-healing and scaling capabilities.
By maintaining the specified number of Pod replicas, ReplicaSets play a vital role in ensuring the reliability and availability of your applications in a Kubernetes cluster. This automatic management of Pods allows developers to focus on application logic rather than worrying about the intricacies of maintaining individual containers.
Series of Events in Kubernetes Deployment
When you run the command kubectl create deployment nginx-deployment --image=nginx --port=80 --replicas=3, a complex series of events unfolds within the Kubernetes cluster. Let’s break down this process step-by-step:
1. Command Execution
- You execute the command on a machine with kubectl installed and configured to interact with your Kubernetes cluster.
2. API Request
- kubectl sends a request to the Kubernetes API server to create a Deployment resource with the specified parameters.
3. API Server Processing
- The API server receives the request, validates it, and processes it.
- If valid, the API server updates the desired state of the cluster stored in etcd.
4. Storage in etcd
- The Deployment definition is stored in etcd, the distributed key-value store used by Kubernetes.
- etcd serves as the source of truth for the cluster’s desired state.
5. Deployment Controller Monitoring
- The Deployment controller, part of the kube-controller-manager, continuously watches the API server for changes to Deployments.
- It detects the new Deployment you created.
6. ReplicaSet Creation
- The Deployment controller creates a ReplicaSet based on the Deployment’s specification.
- This ReplicaSet is responsible for maintaining the stable set of replica Pods.
7. Pod Creation
- The ReplicaSet controller ensures that the desired number of Pods (3 in this case) are created and running.
- It sends requests to the API server to create these Pods.
8. Scheduler Assignment
- The Kubernetes scheduler watches for new Pods in the “Pending” state.
- It assigns these Pods to suitable nodes based on available resources and scheduling policies.
9. Node and Kubelet
- The kubelet on the selected nodes receives the Pod specifications from the API server.
- It pulls the necessary container images (nginx in this case) and starts the containers.
Hierarchical Relationship
- Deployment
- High-Level Manager: Manages the entire lifecycle of an application.
- Creates and Manages ReplicaSets: Reflects the desired state of your application.
- Handles Rolling Updates and Rollbacks: Manages the creation of new ReplicaSets and scaling down old ones.
- ReplicaSet
- Mid-Level Manager: Ensures a specified number of identical Pods are running.
- Maintains Desired State of Pods: Creates and deletes Pods as needed.
- Uses Label Selectors: To identify and manage Pods.
- Pods
- Lowest-Level Unit: The smallest and simplest Kubernetes object.
- Represents a single instance of a running process in your cluster.
Why Use Deployments Over ReplicaSets?
While ReplicaSets are capable of bringing up and healing pods, Deployments offer several advantages:
- Rolling Updates and Rollbacks: Deployments provide built-in support for rolling updates and easy rollbacks.
- Version Control: Deployments maintain a history of rollouts for easy reversion.
- Pause and Resume: Allow pausing and resuming of updates for more control.
- Declarative Updates: Enable declarative updates to applications.
- Advanced Scaling: Provide a higher-level abstraction for scaling complex applications.
- Better Integration: Integrate well with other Kubernetes features like Horizontal Pod Autoscalers.
- Lifecycle Management: Designed to manage the entire lifecycle of an application.
- Simplicity: Offer a higher level of abstraction, simplifying application management.
In essence, while ReplicaSets are powerful, Deployments provide a more comprehensive and user-friendly approach to managing applications in Kubernetes, making them the preferred choice for most scenarios.
Creating a ReplicaSet
In this section, we’ll create a ReplicaSet directly, without using a Deployment. This will help us understand how ReplicaSets work and their self-healing capabilities.
Step 1: Create the ReplicaSet Manifest
Create a file named rs.yml with the following content:
apiVersion: apps/v1kind: ReplicaSetmetadata: name: nginx-replicasetspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80Step 2: Apply the ReplicaSet Manifest
Apply the manifest to create the ReplicaSet:
kubectl apply -f rs.ymlStep 3: Verify the ReplicaSet
Check the status of the ReplicaSet:
kubectl get rsOutput:
NAME DESIRED CURRENT READY AGEnginx-replicaset 3 3 3 23Step 4: Check the Pods
Verify that the ReplicaSet has created three pods:
kubectl get podsOutput:
NAME READY STATUS RESTARTS AGEnginx-replicaset-7zp2v 1/1 Running 0 35snginx-replicaset-q264f 1/1 Running 0 35snginx-replicaset-vj42z 1/1 Running 0 35sStep 5: Test Self-Healing
Delete one of the pods to see if the ReplicaSet recreates it:
kubectl delete pod nginx-replicaset-7zp2vkubectl get podsYou should see that a new pod is created to replace the deleted one.
Step 6: Test Pod Management
Try to add a pod with the same label as the ReplicaSet:
kubectl run nginx-pod --image=nginx --labels="app=nginx"The ReplicaSet will immediately terminate this pod to maintain the desired number of replicas.
Step 7: Clean Up
Delete the ReplicaSet:
kubectl delete rs nginx-replicasetKey Observations
- Naming Convention: Pods created by the ReplicaSet are named after the ReplicaSet followed by a unique identifier (e.g.,
nginx-replicaset-vj42z). - Self-Healing: When a pod is deleted, the ReplicaSet automatically creates a new one to maintain the desired number of replicas.
- Pod Management: The ReplicaSet ensures that only the specified number of pods with matching labels are running. It will terminate excess pods or create new ones as needed.
- Label Importance: The ReplicaSet uses labels to identify which pods it should manage. This is why adding a pod with the same label causes the ReplicaSet to terminate it.
Conclusion
This exercise demonstrates the core functionality of a ReplicaSet:
- Maintaining a specified number of pod replicas
- Self-healing by recreating deleted pods
- Ensuring only the desired number of pods with matching labels are running
While ReplicaSets are powerful for maintaining a set of identical pods, they lack some of the advanced features provided by Deployments, such as rolling updates and easy rollbacks. This is why Deployments are generally preferred for managing applications in Kubernetes.
Creating a Deployment
In this section, we’ll create a Kubernetes Deployment, which is a higher-level abstraction that manages ReplicaSets and provides additional features for managing application lifecycles.
Step 1: Create the Deployment Manifest
Create a file named deployment.yml with the following content:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deploymentspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80Step 2: Apply the Deployment
Apply the manifest to create the Deployment:
kubectl apply -f deployment.ymlStep 3: Verify the Deployment
Check the status of the Deployment:
kubectl get deploymentOutput:
NAME READY UP-TO-DATE AVAILABLE AGEnginx-deployment 3/3 3 3 18sStep 4: Check the ReplicaSet
Verify that the Deployment has created a ReplicaSet:
kubectl get rsOutput:
NAME DESIRED CURRENT READY AGEnginx-deployment-576c6b7b6 3 3 3 34sStep 5: Check the Pods
Verify that the ReplicaSet has created three pods:
kubectl get podOutput:
NAME READY STATUS RESTARTS AGEnginx-deployment-576c6b7b6-b6kgk 1/1 Running 0 46snginx-deployment-576c6b7b6-m8ttl 1/1 Running 0 46snginx-deployment-576c6b7b6-n9cx4 1/1 Running 0 46sStep 6: Test Self-Healing
Delete one of the pods to see if the Deployment (via its ReplicaSet) recreates it:
kubectl delete pod nginx-deployment-576c6b7b6-b6kgkStep 7: Verify Self-Healing
Check that the pods are still up and a new one has been created:
kubectl get podsYou should see that a new pod has been created to replace the deleted one, maintaining the desired number of replicas.
Key Observations
- Deployment Creation: The Deployment creates a ReplicaSet, which in turn creates the desired number of Pods.
- Naming Convention:
- The ReplicaSet name includes the Deployment name and a hash.
- Pod names include the ReplicaSet name and a unique identifier.
- Self-Healing: When a pod is deleted, the Deployment (through its ReplicaSet) automatically creates a new one to maintain the desired state.
- Hierarchy: Deployment -> ReplicaSet -> Pods
- Scalability: The Deployment manages the ReplicaSet, which in turn manages the Pods, providing a scalable and manageable structure.
Conclusion
This exercise demonstrates the key features of a Kubernetes Deployment:
- Creating and managing a ReplicaSet
- Maintaining a specified number of pod replicas
- Self-healing by recreating deleted pods
- Providing a higher-level abstraction for managing applications
Deployments offer several advantages over directly using ReplicaSets:
- Easy rolling updates and rollbacks
- More sophisticated update strategies
- Better integration with other Kubernetes features
By using Deployments, you can manage your application’s lifecycle more effectively, including updates, scaling, and recovery from failures, making it the preferred method for deploying applications in Kubernetes.
Why Do We Need Deployments?
While ReplicaSets are capable of managing pods, Deployments offer several crucial advantages that make them the preferred choice for managing applications in Kubernetes. Let’s explore why Deployments are necessary and how they enhance application management.
Experiment: Updating to a Non-existent Image
- Update the Deployment YAML to use a non-existent image:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deploymentspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx2:latest ports: - containerPort: 80- Apply the updated Deployment:
kubectl apply -f deployment.yml- Check the ReplicaSets:
kubectl get rsOutput:
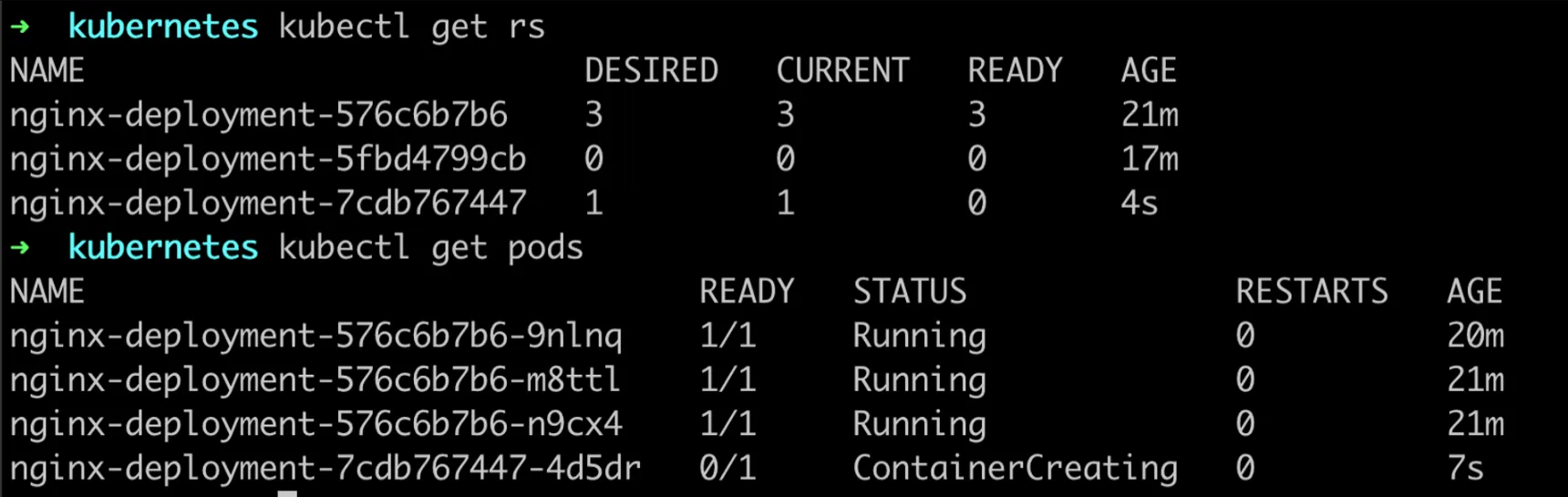
- Check the Pods:
kubectl get podsOutput:
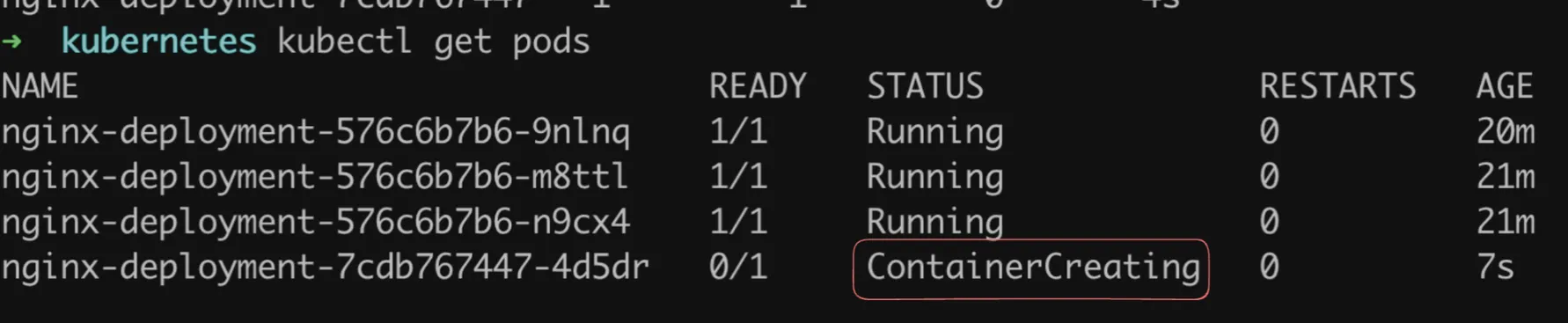
After some time:

Role of Deployments
- Smooth Deployments: Deployments ensure smooth transitions between different versions of your application.
- Failure Handling: If a new image fails, the old ReplicaSet is maintained, ensuring application availability.
- ReplicaSet Management: While ReplicaSets manage pods, Deployments manage ReplicaSets.
Rollbacks
- Check deployment history:
kubectl rollout history deployment/nginx-deployment- Undo the last deployment:
kubectl rollout undo deployment/nginx-deploymentUpdating to PostgreSQL
- Update the Deployment to use PostgreSQL:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deploymentspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: postgres:latest ports: - containerPort: 80- Apply and check the new ReplicaSets and Pods.
- Check pod logs:
kubectl logs -f nginx-deployment-7cdb767447-4d5dr- Update the manifest to include the required environment variable:
spec: containers: - name: nginx image: postgres:latest ports: - containerPort: 80 env: - name: POSTGRES_PASSWORD value: "yourpassword"- Apply the updated manifest and verify that PostgreSQL is running correctly.
Key Advantages of Deployments
- Rolling Updates: Deployments support rolling updates, allowing you to update your application with zero downtime.
- Rollback Capability: Easy rollback to previous versions if issues are detected.
- Version Control: Maintain a history of deployment revisions.
- Pause and Resume: Ability to pause and resume updates for more control over the deployment process.
- Scaling: Easy scaling of applications by updating the replica count.
- Self-healing: Automatically replace failed pods.
- Declarative Updates: Define the desired state, and let Kubernetes handle the details of reaching that state.
Conclusion
While ReplicaSets are powerful for maintaining a set of identical pods, Deployments provide a higher level of abstraction that is crucial for managing the complete lifecycle of an application. They offer sophisticated update strategies, rollback capabilities, and better integration with other Kubernetes features, making them the preferred choice for deploying and managing applications in Kubernetes environments.
How to Expose the App
After creating a Deployment, the next step is to make your application accessible. Let’s go through the process of exposing an NGINX application deployed in Kubernetes.
Step 1: Create a New Deployment
First, let’s create a fresh Deployment for NGINX with 3 replicas:
- Create a file named
deployment.ymlwith the following content:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deploymentspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80- Apply the configuration:
kubectl apply -f deployment.yml- Verify the pods are running:
kubectl get pods -o wideOutput:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESnginx-deployment-576c6b7b6-7jrn5 1/1 Running 0 2m19s 10.244.2.19 local-worker2 <none> <none>nginx-deployment-576c6b7b6-88fkh 1/1 Running 0 2m22s 10.244.1.13 local-worker <none> <none>nginx-deployment-576c6b7b6-zf8ff 1/1 Running 0 2m25s 10.244.2.18 local-worker2 <none> <none>Understanding Pod IPs
The IPs you see (10.244.x.x) are private IPs within the Kubernetes cluster network. These are not directly accessible from outside the cluster. To make your application accessible externally, you need to create a Kubernetes Service.
Step 2: Creating a Service
To expose your application, you’ll need to create a Kubernetes Service. There are different types of Services, but for this example, we’ll use a NodePort Service.
- Create a file named
service.ymlwith the following content:
apiVersion: v1kind: Servicemetadata: name: nginx-servicespec: type: NodePort selector: app: nginx ports: - port: 80 targetPort: 80 nodePort: 30080- Apply the Service configuration:
kubectl apply -f service.yml- Verify the Service is created:
kubectl get servicesYou should see your new service listed.
Step 3: Accessing the Application
Now that you’ve created a NodePort Service:
- The application is accessible on each node of your cluster at port 30080.
- If you’re using a local Kubernetes setup (like Minikube or Kind), you might need to use a specific IP or localhost.
- For cloud-based Kubernetes services, you might need to configure additional networking rules to allow external traffic.
Additional Exposure Methods
-
LoadBalancer: In cloud environments, you can use a LoadBalancer type Service, which provisions an external load balancer.
-
Ingress: For more advanced HTTP routing, you can set up an Ingress controller and Ingress resources.
-
Port-Forwarding: For quick testing, you can use
kubectl port-forward:kubectl port-forward deployment/nginx-deployment 8080:80This forwards local port 8080 to port 80 of a pod in the deployment.
Conclusion
Exposing applications in Kubernetes involves creating Services that define how to access your pods. The method you choose (NodePort, LoadBalancer, Ingress, etc.) depends on your specific requirements and the environment where your Kubernetes cluster is running.
Remember:
- Pod IPs are internal to the cluster and not directly accessible externally.
- Services provide a stable endpoint to access your application.
- Different Service types offer various levels of accessibility and features.
By understanding these concepts, you can effectively expose your Kubernetes applications to external traffic or to other services within your cluster.
Services in Kubernetes
Services in Kubernetes are a crucial abstraction that defines a logical set of Pods and a policy to access them. They provide a stable endpoint for accessing a group of Pods, enabling loose coupling between different parts of an application.
Key Concepts
- Pod Selector: Services use label selectors to identify the set of Pods they target.
- Service Types:
- ClusterIP: Default type. Exposes the Service on an internal IP within the cluster.
- NodePort: Exposes the Service on each Node’s IP at a static port.
- LoadBalancer: Exposes the Service externally using a cloud provider’s load balancer.
- Endpoints: Automatically created and updated by Kubernetes when the selected Pods change.
Creating a Service
- Create a file named
service.yml:
apiVersion: v1kind: Servicemetadata: name: nginx-servicespec: selector: app: nginx ports: - protocol: TCP port: 80 targetPort: 80 nodePort: 30007 type: NodePort- Apply the Service configuration:
kubectl apply -f service.ymlSetting Up a Cluster with Exposed Ports
For local development with Kind, you can create a cluster configuration that maps specific ports:
- Create a file named
kind.yml:
kind: ClusterapiVersion: kind.x-k8s.io/v1alpha4nodes:- role: control-plane extraPortMappings: - containerPort: 30007 hostPort: 30007- role: worker- role: worker- Create the cluster:
kind create cluster --config kind.yml- Apply your Deployment and Service:
kubectl apply -f deployment.ymlkubectl apply -f service.yml- Access the application:
Visit
localhost:30007in your web browser.
Types of Services in Detail
- ClusterIP
- Default Service type
- Exposes the Service on a cluster-internal IP
- Only reachable from within the cluster
- Useful for internal communication between services
- NodePort
- Exposes the Service on each Node’s IP at a static port
- Accessible from outside the cluster using
<NodeIP>:<NodePort> - Automatically creates a ClusterIP Service
- Useful for development and when you have direct access to nodes
- LoadBalancer
- Exposes the Service externally using a cloud provider’s load balancer
- Automatically creates NodePort and ClusterIP Services as well
- Provides an externally-accessible IP address that sends traffic to the correct Port on your cluster nodes
- Ideal for production environments in cloud platforms
Best Practices
- Use Appropriate Service Type: Choose the right type based on your access requirements and environment.
- Label Your Pods: Ensure your Pods have appropriate labels that Services can select.
- Consider Network Policies: Use Network Policies to control traffic flow to your Services.
- Use ReadinessProbes: Implement readiness probes in your Pods to ensure traffic is only sent to Pods that are ready to handle requests.
- Service Discovery: Leverage Kubernetes DNS for service discovery within the cluster.
Conclusion
Services in Kubernetes provide a flexible way to expose applications running on a set of Pods. They abstract away the complexities of pod IP changes and provide a stable endpoint for accessing your applications. By understanding and effectively using Services, you can create robust, scalable, and easily accessible applications in Kubernetes.
Remember, the choice of Service type depends on your specific use case, environment, and how you want your application to be accessed. ClusterIP for internal communication, NodePort for development and testing, and LoadBalancer for production deployments in cloud environments are common patterns.
LoadBalancer Service
A LoadBalancer service in Kubernetes is a powerful way to expose your application to external traffic, especially in cloud environments. It automatically provisions an external load balancer from your cloud provider to route traffic to your Kubernetes service.
Creating a Kubernetes Cluster in Vultr
- Sign up for a Vultr account if you haven’t already.
- Navigate to the Kubernetes section in the Vultr dashboard.
- Create a new Kubernetes cluster, specifying the desired node configuration and region.
- Once the cluster is provisioned, download the kubeconfig file to access your cluster.
Deploying an Application
- Create a file named
deployment.yml:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deploymentspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80- Apply the deployment:
kubectl apply -f deployment.ymlCreating a LoadBalancer Service
- Create a file named
service-lb.yml:
apiVersion: v1kind: Servicemetadata: name: nginx-servicespec: selector: app: nginx ports: - protocol: TCP port: 80 targetPort: 80 type: LoadBalancer- Apply the service:
kubectl apply -f service-lb.ymlKey Points About LoadBalancer Services
- Cloud Provider Integration: LoadBalancer services work by integrating with your cloud provider’s load balancing service.
- External IP: When you create a LoadBalancer service, Kubernetes will provision an external IP address that you can use to access your service.
- Automatic Configuration: The cloud provider automatically configures the load balancer to route traffic to your service.
- Cost Consideration: Be aware that using a LoadBalancer service typically incurs additional costs from your cloud provider for the load balancer resource.
- Health Checks: The load balancer automatically performs health checks on your service’s pods.
- SSL/TLS Termination: Many cloud providers allow you to configure SSL/TLS termination at the load balancer level.
Checking the Service Status
After applying the LoadBalancer service, you can check its status:
kubectl get servicesLook for the EXTERNAL-IP column. It might take a few minutes for the external IP to be provisioned.
Accessing Your Application
Once the external IP is provisioned, you can access your application using this IP address:
http://<EXTERNAL-IP>Best Practices
- Security Groups: Ensure your cloud provider’s security groups or firewall rules allow traffic to the load balancer.
- Monitoring: Set up monitoring for your load balancer to track metrics like request count, latency, and error rates.
- SSL/TLS: For production workloads, configure SSL/TLS on your load balancer for secure communication.
- Session Affinity: If your application requires session stickiness, configure session affinity on the LoadBalancer service.
- Health Checks: Implement robust health checks in your application to ensure the load balancer routes traffic only to healthy pods.
Conclusion
LoadBalancer services in Kubernetes provide a straightforward way to expose your applications to the internet when running in cloud environments. They abstract away the complexities of managing external load balancers, making it easier to deploy and scale your applications.
Remember that while LoadBalancer services are convenient, they come with additional costs and are specific to cloud environments. For on-premises or bare metal Kubernetes clusters, you might need to look into alternatives like MetalLB or using Ingress controllers with NodePort services.
Series of Events
This section outlines the step-by-step process of creating a Kubernetes cluster, deploying an application, and exposing it using different service types.
Step 1: Create Your Cluster
- Create a file named
kind.yml:
kind: ClusterapiVersion: kind.x-k8s.io/v1alpha4nodes:- role: control-plane extraPortMappings: - containerPort: 30007 hostPort: 30007- role: worker extraPortMappings: - containerPort: 30007 hostPort: 30008- role: worker- Create the cluster:
kind create cluster --config kind.yml --name localThis creates a local Kubernetes cluster with one control-plane node and two worker nodes, with specific port mappings.
Step 2: Deploy Your Pod
- Create a file named
deployment.yml:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deploymentspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80- Apply the deployment:
kubectl apply -f deployment.ymlThis creates a deployment with 3 replicas of NGINX pods.
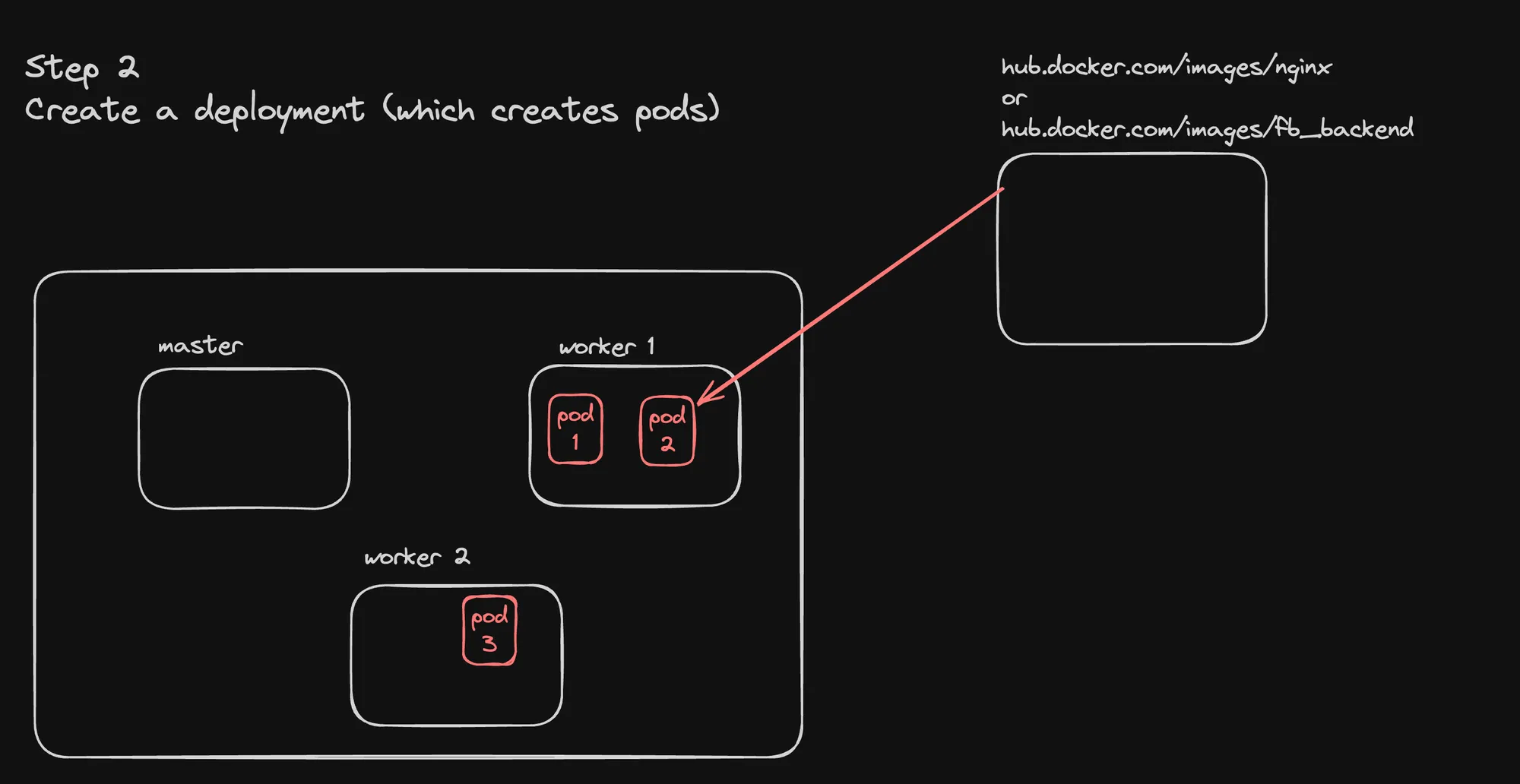
Step 3: Expose Your App over a NodePort
- Create a file named
service.yml:
apiVersion: v1kind: Servicemetadata: name: nginx-servicespec: selector: app: nginx ports: - protocol: TCP port: 80 targetPort: 80 nodePort: 30007 type: NodePort- Apply the service:
kubectl apply -f service.ymlThis creates a NodePort service, making your application accessible on port 30007 of any node in the cluster.
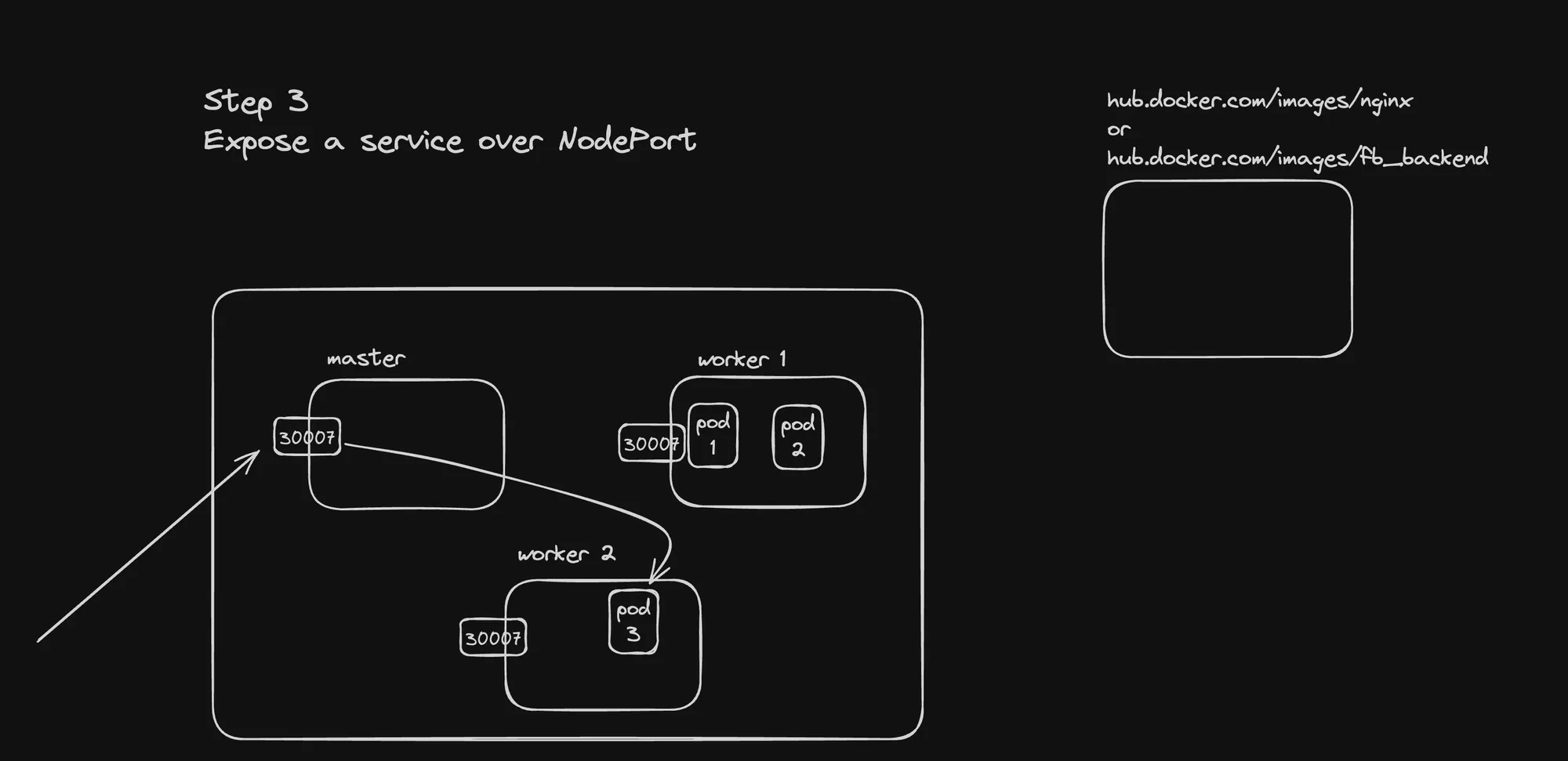
Step 4: Expose it over a LoadBalancer
- Create a file named
service-lb.yml:
apiVersion: v1kind: Servicemetadata: name: nginx-servicespec: selector: app: nginx ports: - protocol: TCP port: 80 targetPort: 80 type: LoadBalancer- Apply the LoadBalancer service:
kubectl apply -f service-lb.ymlThis creates a LoadBalancer service, which would provision an external load balancer in a cloud environment.
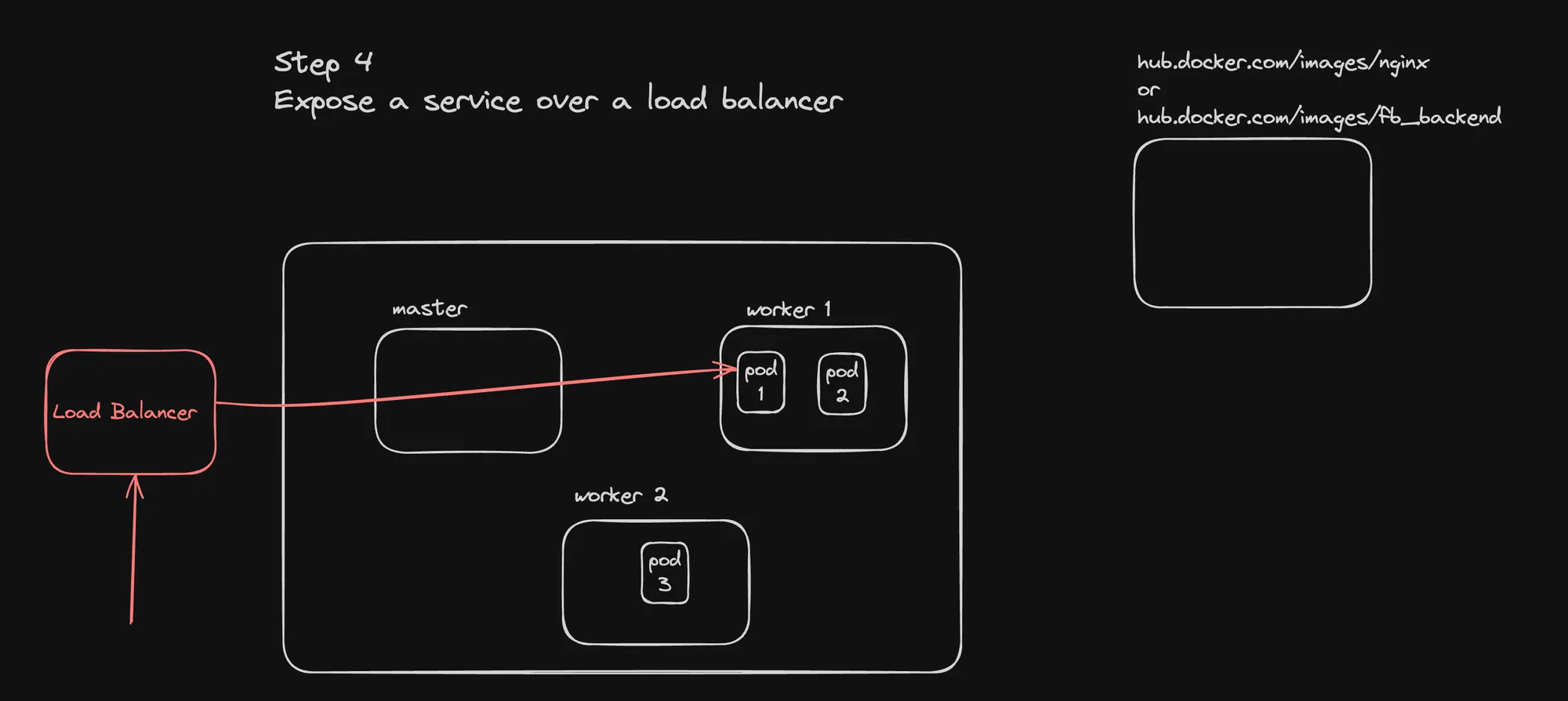
Key Observations
- Cluster Creation: The Kind configuration allows for custom port mappings, useful for local development and testing.
- Deployment: The deployment ensures that a specified number of pod replicas (3 in this case) are running at all times.
- NodePort Service: Makes the application accessible on a specific port (30007) on all nodes. This is useful for development and when you have direct access to node IPs.
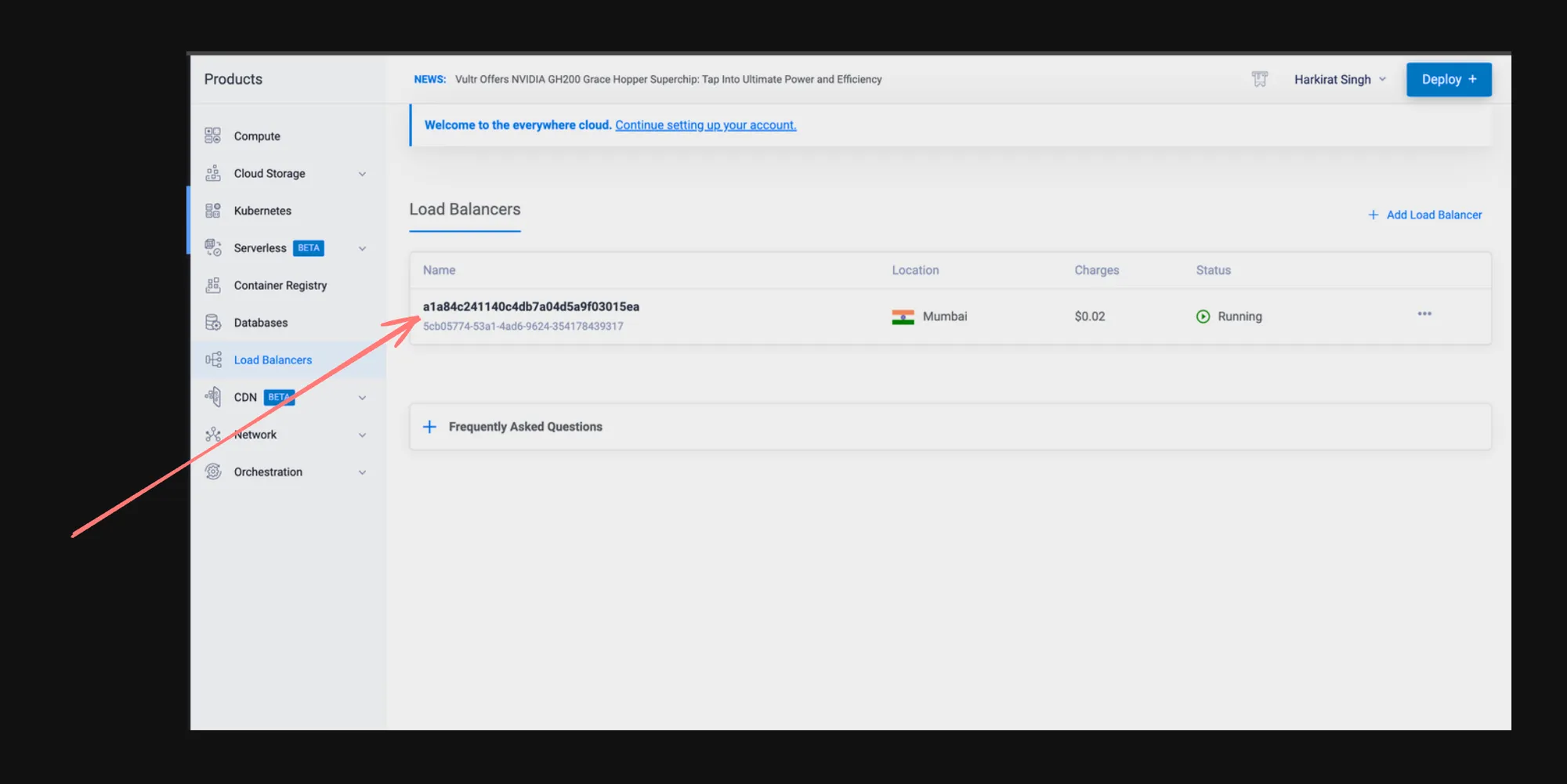
- LoadBalancer Service: In a cloud environment, this would provision an external load balancer. In a local setup like Kind, it might not provide an external IP.
- Cloud Dashboard: In a real cloud environment, you would see the load balancer resource in your cloud provider’s dashboard.
Best Practices
- Resource Management: Always specify resource requests and limits in your deployments for better cluster resource management.
- Health Checks: Implement readiness and liveness probes in your pods for better service health management.
- Security: In a production environment, consider using network policies to control traffic flow.
- Monitoring: Set up monitoring and logging for your services and pods.
- Version Control: Keep all your Kubernetes manifests in version control.
Conclusion
This series of events demonstrates the typical workflow for deploying and exposing an application in Kubernetes. It showcases the flexibility of Kubernetes in handling different exposure methods (NodePort for development, LoadBalancer for production cloud environments).
Remember that while this example uses NGINX, the same principles apply to deploying and exposing any containerized application. The choice between NodePort and LoadBalancer often depends on your specific environment and requirements.