Week 22.3 Indexing in Postgres
In this offline lecture, Harkirat covers Indexing in PostgreSQL, a crucial aspect of database performance optimization. He explains the fundamentals of indexes, their types, and their role in improving query efficiency. Harkirat delves into complex indexes, such as multicolumn and partial indexes, and their use cases. Additionally, he explores Indexing in Prisma, an Object-Relational Mapping (ORM) tool for Node.js, demonstrating how to define and manage indexes within the Prisma schema.
Indexing in Postgres
Indexing is a crucial technique in database management that significantly improves query performance. This section will guide you through the process of creating a PostgreSQL database, inserting dummy data, and observing the impact of indexing on query performance.
Setting Up PostgreSQL Locally
Step 1: Create a PostgreSQL Database Locally
-
Run PostgreSQL using Docker:
Terminal window docker run -p 5432:5432 -e POSTGRES_PASSWORD=mysecretpassword -d postgres -
Connect to the PostgreSQL container:
Terminal window docker exec -it <container_id> /bin/bashpsql -U postgres
Step 2: Create the Schema for a Simple Medium-like App
-
Create the
userstable:CREATE TABLE users (user_id SERIAL PRIMARY KEY,email VARCHAR(255) UNIQUE NOT NULL,password VARCHAR(255) NOT NULL,name VARCHAR(255)); -
Create the
poststable:CREATE TABLE posts (post_id SERIAL PRIMARY KEY,user_id INTEGER NOT NULL,title VARCHAR(255) NOT NULL,description TEXT,image VARCHAR(255),FOREIGN KEY (user_id) REFERENCES users(user_id));
Step 3: Insert Dummy Data
-
Insert data into the tables:
DO $$DECLAREreturned_user_id INT;BEGIN-- Insert 5 usersFOR i IN 1..5 LOOPINSERT INTO users (email, password, name) VALUES('user'||i||'@example.com', 'pass'||i, 'User '||i)RETURNING user_id INTO returned_user_id;FOR j IN 1..500000 LOOPINSERT INTO posts (user_id, title, description)VALUES (returned_user_id, 'Title '||j, 'Description for post '||j);END LOOP;END LOOP;END $$;
Step 4: Measure Query Performance Without Indexes
-
Run a query to get all posts of a user and log the time it took:
EXPLAIN ANALYSE SELECT * FROM posts WHERE user_id=1 LIMIT 5; -
Focus on the execution time.
Step 5: Add an Index to user_id
-
Create an index on the
user_idcolumn:CREATE INDEX idx_user_id ON posts (user_id); -
Run the same query again and notice the execution time:
EXPLAIN ANALYSE SELECT * FROM posts WHERE user_id=1 LIMIT 5;
Observations
- Without Indexes: The query scans the entire
poststable to find the relevant rows, which can be slow for large datasets. - With Indexes: The query uses the index to quickly locate the relevant rows, significantly reducing the execution time.
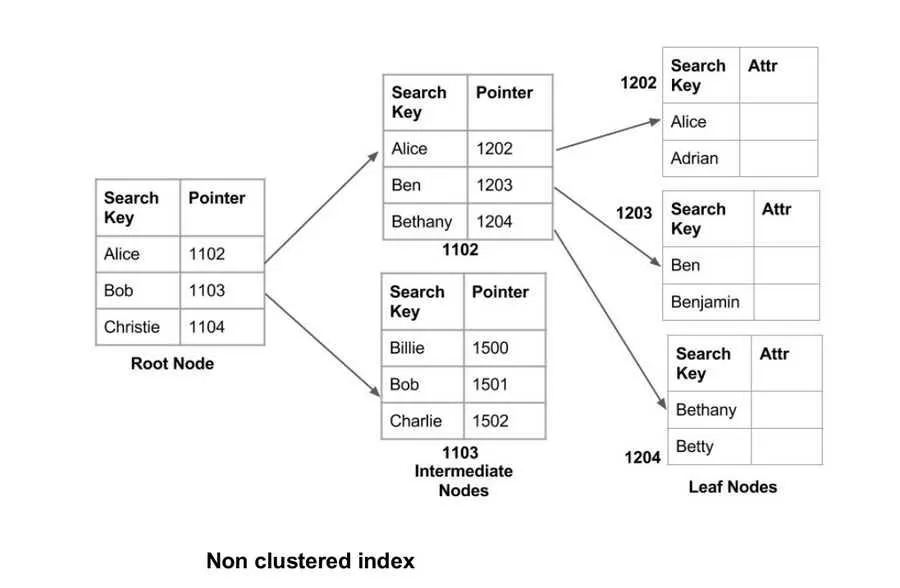
How Indexing Works (Briefly)
When you create an index on a field, a new data structure (usually a B-tree) is created that stores the mapping from the index column to the location of the record in the original table. The search on the index is usually $$O(\log n)$$, which is much faster than a full table scan.
- Without Indexes: The database performs a full table scan, which is $$O(n)$$.
- With Indexes: The database uses the index to perform a search, which is $$O(\log n)$$.
In PostgreSQL, the data pointer in the index is the page and offset at which the record can be found. Think of the index as the appendix of a book and the location as the page and offset where the data can be found.
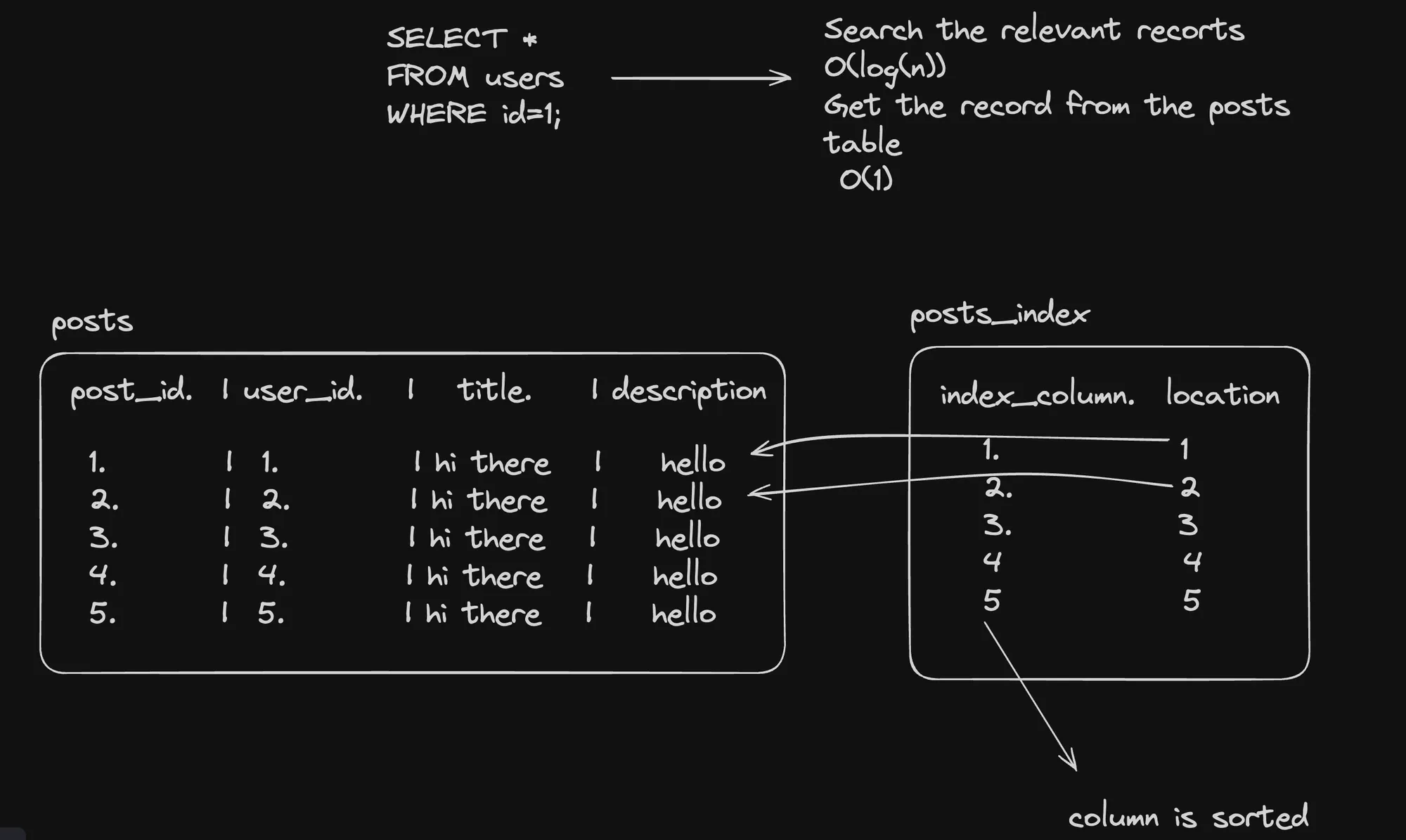
Without Indexes
- Table Structure: The
poststable contains columnspost_id,user_id,title, anddescription. - Query Execution: The query
SELECT * FROM users WHERE id=1;performs a full table scan, which is $$O(n)$$. This means the database scans every row in thepoststable to find the relevant records, which is inefficient for large datasets.

With Indexes
- Table Structure: The
poststable remains the same, but an additionalposts_indextable is created. - Index Structure: The
posts_indextable containsindex_columnandlocation. Theindex_columnstores the values of theuser_idcolumn from thepoststable, and thelocationstores the corresponding row location. - Query Execution: The query
SELECT * FROM users WHERE id=1;now uses the index to search the relevant records, which is $$O(\log n)$$. The database quickly finds the relevant rows using the index and retrieves the records from thepoststable, which is $$O(1)$$.
By following these steps and understanding the impact of indexing, you can significantly improve the performance of your queries in PostgreSQL.
Complex Indexes
Complex indexes, also known as composite indexes, are indexes that include more than one column. They are particularly useful for optimizing queries that filter on multiple columns. This section will elaborate on how complex indexes work and how they can be used to minimize the time for database queries.
Understanding Complex Indexes
Key Points:
- Multi-Column Indexing:
- You can create an index on more than one column to optimize queries that filter on multiple columns.
- For example, if you frequently query posts by both
user_idandtitle, a composite index on these columns can significantly speed up these queries.
- Example Scenario:
- Suppose you want to retrieve all posts of a user with a given ID and a specific title. This query can be optimized using a composite index.
Step-by-Step Guide
Step 1: Create a Composite Index
-
Create an index on the
user_idandtitlecolumns:CREATE INDEX idx_posts_user_id_title ON posts (user_id, title);
Step 2: Measure Query Performance Before and After Adding the Index
-
Run the query before adding the index:
EXPLAIN ANALYSE SELECT * FROM posts WHERE user_id=1 AND title='Title 1'; -
Add the composite index:
CREATE INDEX idx_posts_user_id_title ON posts (user_id, title); -
Run the query again after adding the index:
EXPLAIN ANALYSE SELECT * FROM posts WHERE user_id=1 AND title='Title 1';
Observations
- Before Indexing: The query performs a full table scan or uses a single-column index, which can be inefficient for large datasets.
- After Indexing: The query uses the composite index to quickly locate the relevant rows, significantly reducing the execution time.
How Composite Indexing Works
When you create a composite index, a new data structure (usually a B-tree) is created that stores the mapping from the combination of the indexed columns to the location of the record in the original table. The search on the composite index is usually $$O(\log n)$$, which is much faster than a full table scan.
- Without Composite Indexes: The database may perform multiple scans or a full table scan, which is $$O(n)$$.
- With Composite Indexes: The database uses the composite index to perform a search, which is $$O(\log n)$$.
Practical Example
-
Create the Composite Index:
CREATE INDEX idx_posts_user_id_title ON posts (user_id, title); -
Run the Query Before Adding the Index:
EXPLAIN ANALYSE SELECT * FROM posts WHERE user_id=1 AND title='Title 1';- Expected Result: The query will likely perform a full table scan, resulting in higher execution time.
-
Run the Query After Adding the Index:
EXPLAIN ANALYSE SELECT * FROM posts WHERE user_id=1 AND title='Title 1';- Expected Result: The query will use the composite index, resulting in significantly reduced execution time.
By creating composite indexes, you can optimize complex queries that filter on multiple columns, significantly improving query performance. This is especially useful for large datasets where full table scans can be very slow. Understanding and utilizing composite indexes effectively can lead to more efficient and faster database operations.
Indexes in Prisma
Indexes in Prisma are a way to optimize database queries by creating an index on one or more fields in a model. Indexes can significantly improve the performance of queries that filter, sort, or join on the indexed fields. This section will elaborate on how to define and use indexes in Prisma, with a focus on minimizing query time.
Reference
For more detailed information, refer to the official Prisma documentation on indexes: Prisma Indexes Documentation.
Adding an Index to a Model in Prisma
To add an index to a model in Prisma, you can use the @@index attribute for composite indexes or the @unique attribute for unique indexes. Here is an example schema with indexes:
model User { id String @id @default(uuid()) username String @unique email String @unique posts Post[] createdAt DateTime @default(now()) updatedAt DateTime @updatedAt}
model Post { id String @id @default(uuid()) title String content String? published Boolean @default(false) createdAt DateTime @default(now()) updatedAt DateTime @updatedAt userId String user User @relation(fields: [userId], references: [id])
@@index([userId])}Explanation of the Example
- User Model:
id: Primary key with a default UUID.username: Unique index to ensure no two users have the same username.email: Unique index to ensure no two users have the same email.posts: Relation to thePostmodel.createdAt: Timestamp for when the user was created.updatedAt: Timestamp for when the user was last updated.
- Post Model:
id: Primary key with a default UUID.title: Title of the post.content: Optional content of the post.published: Boolean flag to indicate if the post is published.createdAt: Timestamp for when the post was created.updatedAt: Timestamp for when the post was last updated.userId: Foreign key to theUsermodel.user: Relation to theUsermodel.@@index([userId]): Composite index on theuserIdfield to optimize queries that filter posts by user ID.
Introducing Indexes in Daily Code
To introduce indexes in the daily code, you can follow these steps:
-
Identify the Fields to Index:
- Look for fields that are frequently used in
WHERE,ORDER BY, orJOINclauses.
- Look for fields that are frequently used in
-
Modify the Prisma Schema:
- Add the
@@indexor@uniqueattributes to the relevant fields in your Prisma schema.
- Add the
-
Example:
model DailyCode {id String @id @default(uuid())userId Stringcode StringcreatedAt DateTime @default(now())updatedAt DateTime @updatedAt@@index([userId, createdAt])} -
Generate Prisma Client:
Terminal window npx prisma generate -
Use the Index in Queries:
const dailyCodes = await prisma.dailyCode.findMany({where: {userId: 'some-user-id',},orderBy: {createdAt: 'desc',},});
By following these steps and understanding the impact of indexing, you can significantly improve the performance of your queries in Prisma.